
声学相关
2400 Words|Read in about 11 Min|本文总阅读量次
本文主要记录一些关于声学相关的概念和资料,主要是整体的一些概念,细节方面后续会单独有篇章去介绍。
0认识声音
0.1声音与哲学
在探索声音前,我们先来看个有趣的问题:
有人在知乎上问:
如果世界上没有声音那世界会怎么样?
结果最高票的回答是:
世界上是没有声音的!!声音不是客观存在!!
如果世界上没有声音那世界会怎么样? - 李如春的回答 - 知乎
看完文章是不是非常惊喜,原来声音的问题都可以上升到哲学层面了。
简单来说,声音的产生有三个要素, 离开任何一环,都没有声音产生。
- 物体振动产生的波;
- 传播媒介(如空气);
- 人耳的接收与大脑解读。
因此,声音是人耳对一定频率振动波(振动频率16HZ~20000HZ的波)的反应和解读,而非客观实在。 也就是说自然界中只存在振动波和传播媒介,而没有"响"声。
0.2最早的录音
最早录音也许要追溯到130年前,具体是谁,直到今天都一直有争议,很多人说是爱迪生,很多人说是贝尔,也有很多人说是法国的scott,这里我们就认为是一个外国人好了。
早期的录音机器大概是这个样子的,需要一个大喇叭收集声音,然后手摇传动轴,声音被记录在一张煤灰纸上。

0.3最早的录音
最早录音也许要追溯到130年前,具体是谁,直到今天都一直有争议,很多人说是爱迪生,很多人说是贝尔,也有很多人说是法国的scott,这里我们就认为是一个外国人好了。
早期的录音机器大概是这个样子的,需要一个大喇叭收集声音,然后手摇传动轴,声音被记录在一张煤灰纸上。
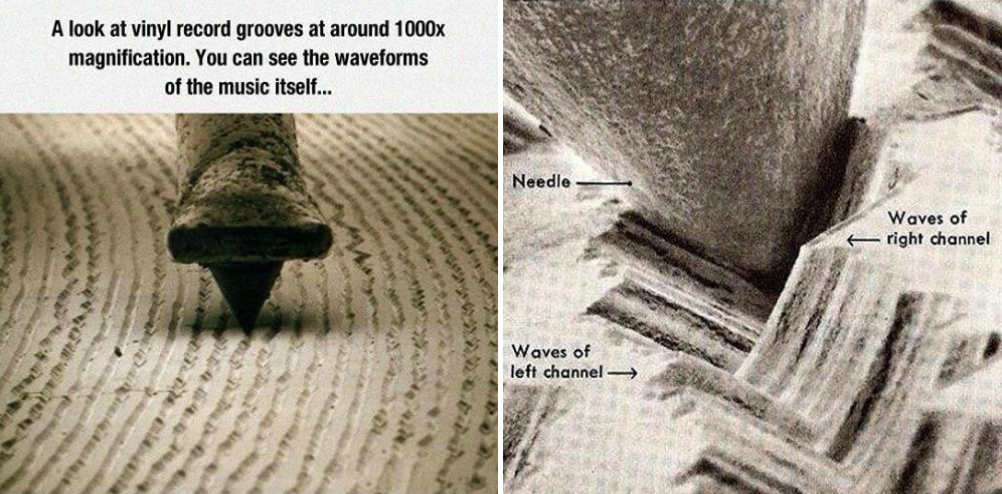
播放的原理是唱针接触到黑胶纹路,产生摩擦,还原了当时刻录的震动声波,再通过电音把震动声放大数千倍,就形成了黑胶音乐,原始胶片还原度最高了。
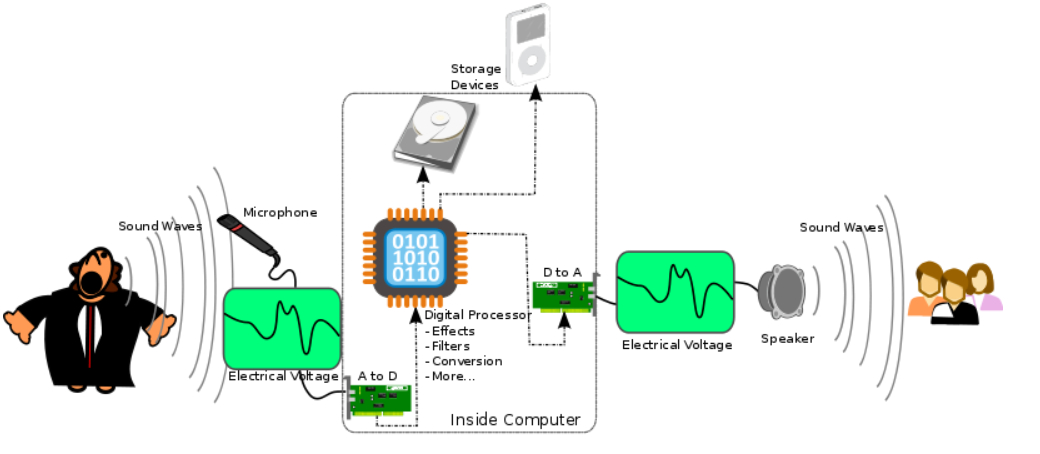
0.4数字化记录
随着时代的发展,通过黑胶刻录的时代逐步过去,接着是磁带技术的新老交替, 而如今,数字电子技术的发展和集成电路技术的进步,录音机的性能和功能都达到了前所未有的水平。 这里我们简单来介绍一下
-
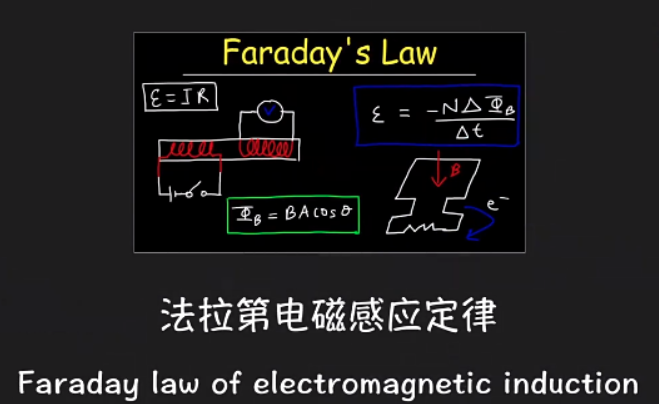
麦克风工作原理。以常见麦克风分为动圈和电容为例: 动圈麦克风(Dynamic Micphone): 原理要从法拉第电磁感应定律说起:
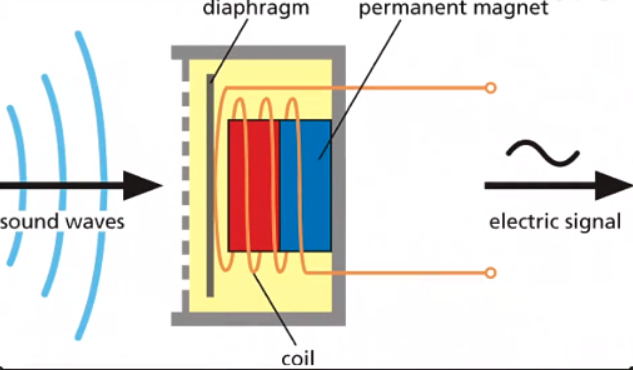
简单说就是封闭线圈在磁场中做切割运动,就会产生感应电压。 下面就是麦克风解刨放大图,可以看到一层薄膜和金属线圈,薄膜用来接受外界空气震动,推动线圈在磁场中做切割运动,从而将声音的震动转换成电信号。
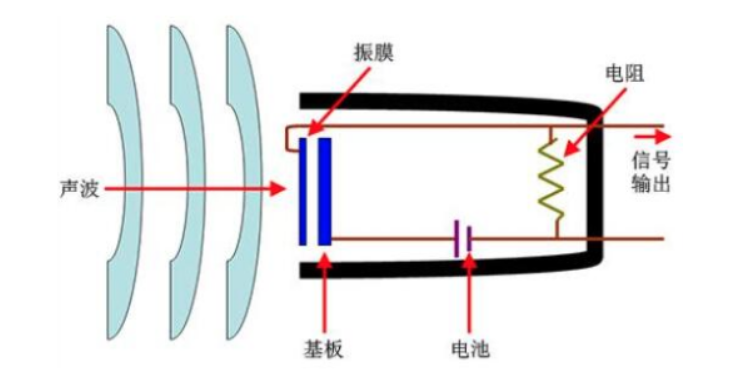
电容麦克风(Condenser Micphone): 电容式麦克风有两块金属极板,其中一块表面涂有驻极体薄膜并将其接地,另一极板接在场效应晶体管的栅极上,栅极与源极之间接有一个二极管,当驻极体膜片本身带有电荷,表面电荷地电量为Q,板极间地电容量为C,则在极头上产生地电压U=Q/C,当受到振动或受到气流地摩擦时,由于振动使两极板间的距离改变,即电容C改变,而电量Q不变,就会引起电压的变化,电压变化的大小,反映了外界声压的强弱。当前嵌入式设备中,大部分采用体积小,灵敏度高的电容麦克风。常用的两种电容式麦克风:驻极体电容麦克风(ECM)和微机电麦克风(MEMS Micphone 也称硅麦)。
-
数字化记录和播放过程
通过接受外界声音的震动,从而改变测量点的电压值,将采集的值进行一定格式的编码
PCM记录在计算机中存储为原始音频文件。播放则按照存储的格式从新将数据取出,转换成数字信号传递给喇叭进行播放。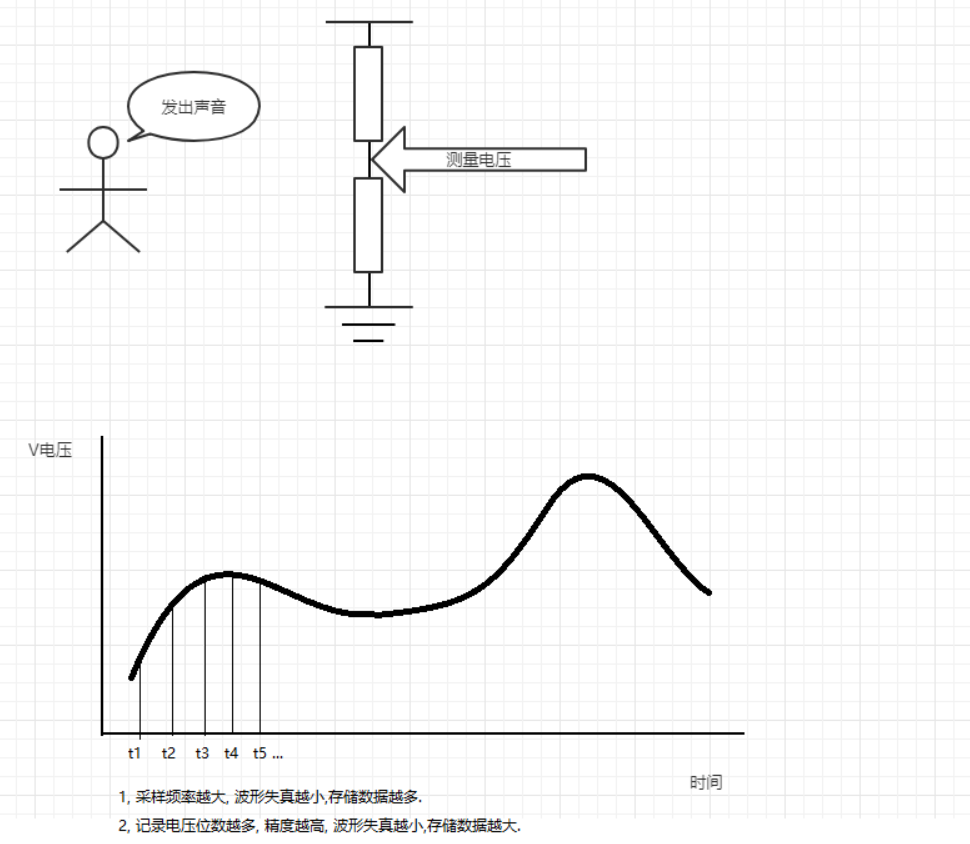
-
采样参数说明
- 采样率:一秒需要采集多少个点数据;
- 采样精度:每个数据需要多少位来存储;
- 采样通道:需要采样多少个通道,比如人就是双通道录音(左耳和右耳),单通道播放(一个嘴巴);
- 录音为什么是16k/16bit? 16k采样频率: 实际的情况下,采集频率往往比信号的实际频率要高出5到10倍以上。因为采集频率仅仅高于信号频率的2倍(乃奎斯特定律)的情况下,是很难获取测量的精度的。 而人的发音频率集中在80HZ~1200HZ(2018年,中国达人王晓龙以5,243Hz的成绩打破了吉尼斯世界纪录),所以16KHZ采样频率能够尽量减少失真的情况采集到人的声音信号。 16bit采样位数: 2^16=65536,20log(65536)约等于96dB的动态范围,足够覆盖一般场景,比如覆盖安静的夜晚(30dB)到球磨机工作(约120dB)。
- 播放的音频为什么是44.1k 44.1k播放音频: 因为人耳的听觉范围大概在20Hz~20kHz,如果想还原20khz的音频采样频率至少要40khz ,但是梳状滤波器不可能是完美的,截止频率不能完全截断,所以需要将通带适当放开,增加一个大概10%衰减缓冲的带宽,所以就需要44k的播放音频,具体为什么是44.1k,这个就和播放的格式和数据的编码传输有关。
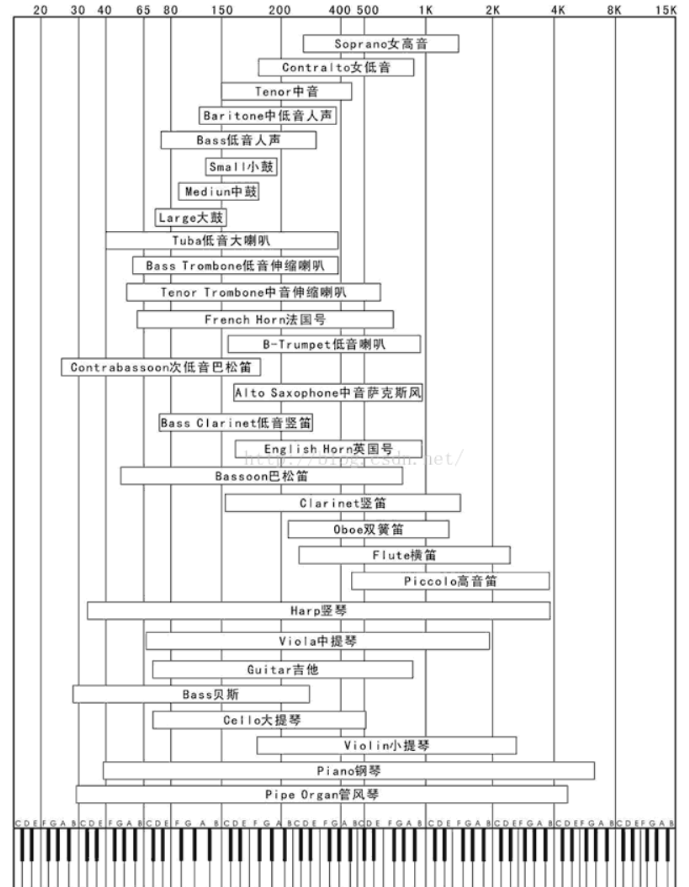
说钢琴是乐器国王不是没有道理的
1语音技术
玩过智能设备的朋友比较清楚现在的语音交互,可以通过“唤醒”对设备发起一个指令,让设备最终执行某个或者某些动作。
首先有几个疑问
11)为什么需要“信号处理”呢?
22)为什么要“语音唤醒”呢?
33)“语音识别”是什么?
44)为什么要“对话管理”?
1.1语音的诉求和赋能
在远古时代,那些对外界震动无法理解和做出反应的人可能被躲在草丛里,蹑手蹑脚的野兽吃掉,而能听到声音就成了生存本能。 也许正是因为如此,大脑对声音会更情有独钟和信赖,在人类逐步形成群居特性后,“情感的表达”,“沟通交流” 的诉求就越发突出, 而用语音表达,成了这些述求最自然的选择。
在文明的发展过程中,我们总是在不停的发明创造工具,希望通过工具改变效率。如今越来越多智能设备的出现, 很大程度方便了我们的日常生活,随之而来的是设备的复杂度也越高,如何用最简单的方式和设备交互呢?
用手点屏幕吗?👆 这是用户理解设备后的交互方式,那设备理解用户的交互方式是什么?
这也许要回归到人和人交互最习惯的方式:语音。
1.2人机对话
要人机对话,设备至少得能感知外界震动,能做出回应,最关键的是能理解说话的意思。 所以基于以上三点,设计出来的对话系统由以下模块组成。
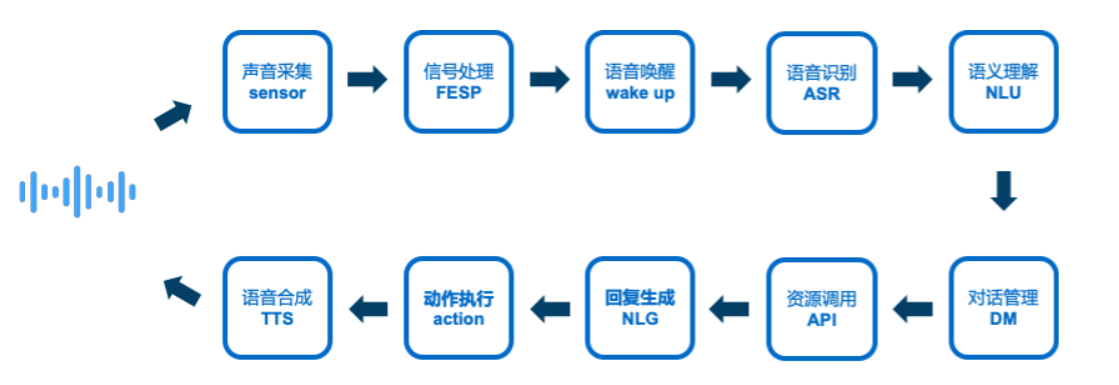
回答下上面的问题
1)为什么需要“信号处理”呢?
因为我们生活的环境充满了噪声,有来自车辆行驶的噪声,有空调吹风的噪声,还有墙壁反射形成的混响, 我们需要在噪声中找到声源,通过信号处理,让声源信号更加清晰,这样为后面更准确的识别打好基础。
2)为什么要“语音唤醒”呢?
“语音唤醒”是什么?在人机对话中,每次发起语音对话前需要先通过特定的词组来触发对话。 就像上课时老师要学生回答问题,需要先叫某个同学的名字,再开始对答一样。 然而在语音交互中,最理想的情况应该是没有唤醒操作,任何时候我们发出的语音指令设备都应该做出相应。 但是受限于当前设备性能算力,功耗,网络带宽等条件,如果一直识别,大量无意义的输入解析会加重设备和 网络负担,特别是功耗要求严格的移动设备。
3)“语音识别”是什么?
举个例子:在上课时,你想把你的想法传达给同桌,又不能说话,你会怎么做? 你也许会把你想说的话写在一张字条上,然后传给他,他看文字也能明白你的意思。 这就是语音识别,是一个声音抽象成文字的过程。
4)为什么要“对话管理”?
这都要怪我们太懒了,我们对话时,常常会省略掉一些背景或之前提过的信息,比如天气等。
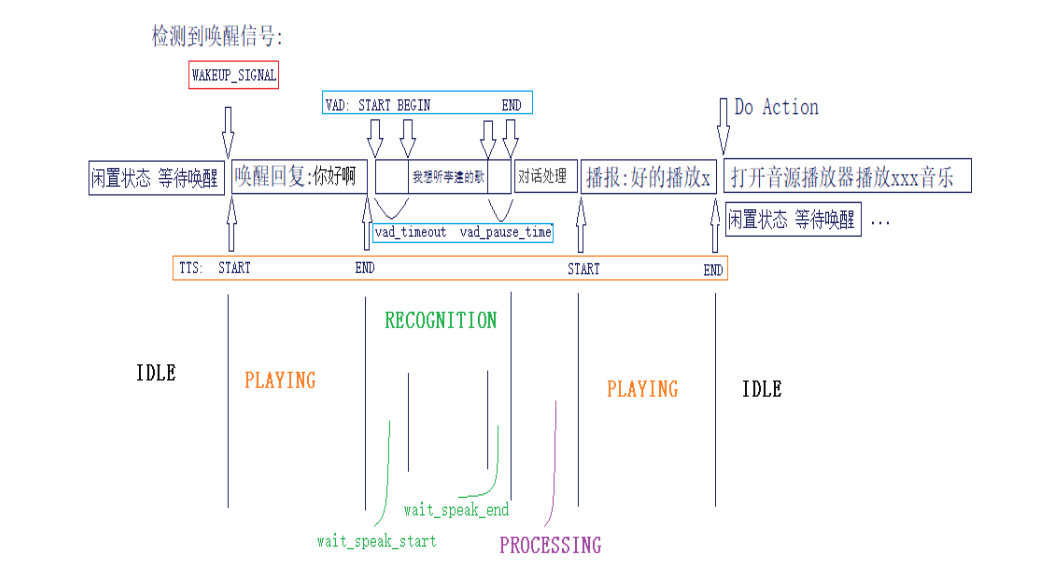
1.3人机对话情景分析
下面我们会针对一个具体的语音对话场景, 来简单分析一下,在一轮人机对话中,涉及到哪些语音模块和状态的切换。
对话开始 人:天猫精灵 (唤醒信号发出) 机:你好 (唤醒回复) 人:我要听周杰伦的歌 (用户指令) 识别语义理解… 机:好的,播放周杰伦的夜曲 机:打开音乐播放器播放指定音乐 对话结束
1.3.1语音状态
一轮人机对话,涉及的语音状态可以简单分为
| 状态 | 英文 |
|---|---|
| 闲置状态 | (IDLE) |
| 播报状态 | (PLAYING) |
| 识别状态 | (WAIT_SPEAK_START, RECOGNITION,WAIT_SPEAK_END) |
| 处理状态 | (PROCESSING) |
状态和状态之间切换则需要以下一些信号触
语音端点检测 (VAD),用于断句的 唤醒信号 (WAKEUP_SIGNAL),比如天猫精灵的唤醒词
1.3.2识别状态
识别状态细分有三个:
- 播报结束后刚开启识别时,但是这时候用户可能没有说话,到检测到用户说话是有一个短暂的WAIT_SPEAK_START状态, 如果这个状态持续时间过长的话,对话会提示“您没有说话哦”,让整个对话体验更加自然。
- 当WAIT_SPEAK_START超时前检查到用户开始说话,会进入RECOGNITION状态,这个状态会持续采集用户输入音频,通过识别引擎将音频转化为文本内容。
- 当用户说完话后,到开始处理前,有一个说话结束判断,类似微信发送语音消息,说完话松开录音按键动作。而这里的人机对话是不需要用户按住说话按钮, 全部依靠语音算法(VAD)自动检测判断。这段时间称为WAIT_SPEAK_END, 根据超时参数(一般600ms),语音会有一个自动截断处理,但是如果这时候除了说话人以外有其他较大噪声存在, 会影响这个状态判断,导致用户指令说完后迟迟没有进入处理阶段。
大部分情况,WAIT_SPEAK_START, WAIT_SPEAK_END是不需要开发者操作,相关操作已经封装在语音识别引擎中,开发者只需要根据产品需求,在初始化时设置对应的接口参数即可,这里将其细分出来是方便开发者在对接过程中遇到这类问题有一个判断方向。
如果在上面的基础上加入回声抵消(AEC)之后
我们将上面的对话时序图和当前(加入AEC算法)时序图进行对比,最大的差别就是加入AEC算法后,你可以在机器播报的中途输入语音指令,这样可以给到用户更自由的对话交互。 在上面例子可以看到VAD的检测和ASR的开启都放在唤醒播报结束后才开启,这是为了避免机器播报语(TTS)干扰了识别,但是如果设备提供了参考回路数据, 并集成了AEC算法,这个时候可以在唤醒触发后就开启识别,可以更快的响应用户语音输入。而不用再等待设备播报完再交互,同时也为后续播报提供了打断支持,如下图。
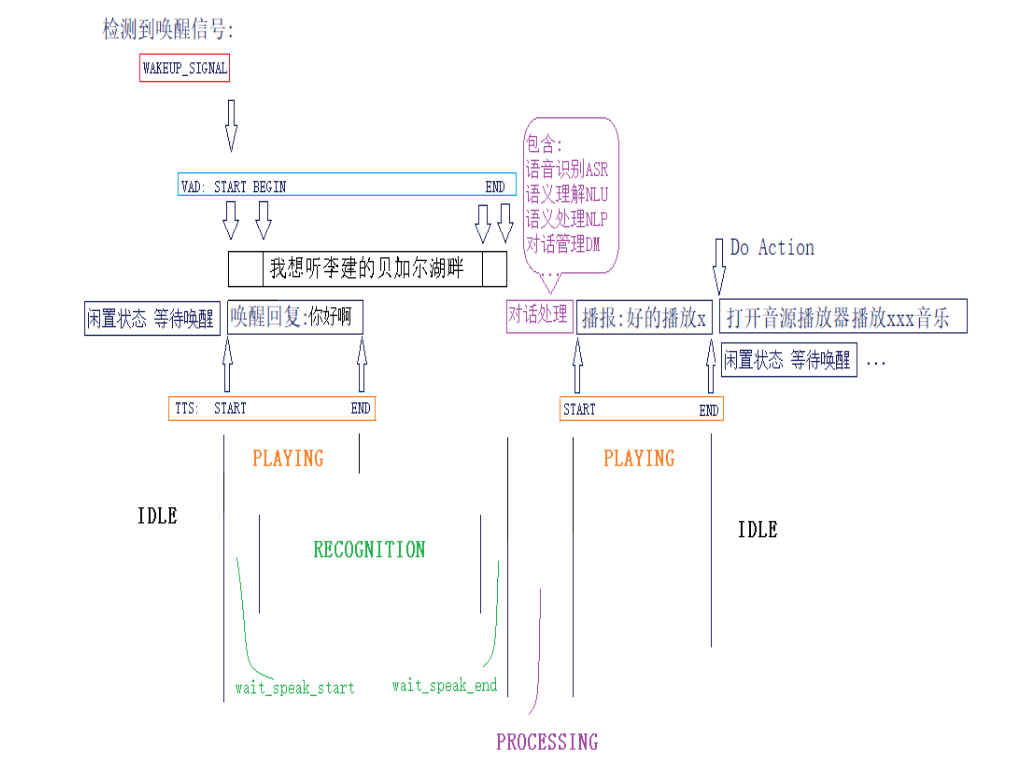
- 误唤醒提升;
- 识别率下降(识别结果混入了播报语);
- 打断效果差或无法打断;
- 以及vad判断不准确带来识别和oneshot功能体验差等问题。
1.4专业名词解释
| 缩写 | 全拼 | 解释 | 举例说明 |
|---|---|---|---|
AEC |
Acoustic Echo Cancellation | 回声消除,将本机播放的音频在录音数据剔除 | 播放音乐的时候想唤醒,或者tts播报的时候想打断 |
AGC |
Automatic Gain Control | 自动增益控制 | 一般用在远场通话或者录音效果上,根据音频信号强度动态调整增益控制实现这种功能电路检查AGC环 |
API |
Application Programming Interface | 应用程序编程接口 | 常用于不同层面,不同开发团队等对接时使用,具体实现前,先对接API,后续更新接口不变,具体实现更新 |
APK |
Android Package | Android应用程序安装包 | Android应用开发后打包程序,用于安装和分发 |
ASR |
Automatic Speech Recognition | 自动语音识别技术 | 将声音转成文字 |
AOP |
Acoustic Over-loading Power | 声学过载点 | 一般作为麦克风选型参考指标,如常用的AOP>=120dB SPL |
dB |
- | 分贝 | 是量度两个相同单位之数量比例的计量单位,可用于度量声音强度 |
BF |
Beam Forming | 波束成形,对指角度定声音做增强 | 经常用在远场语音场景,提高声源方向信噪比 |
BSS |
Blind Signal/Source Separation | 盲源分离,在不知道源信号在哪里,从噪声中把声源分离出来 | 比如在酒吧嘈杂的环境,无法确认声源方向,则只能根据声音特征分离出需要的声音 |
DM |
Dialogue Management | 对话管理 | 多轮对话或者复杂对话逻辑需要,让设备对话更符合人的思维 |
DNN |
Deep Neural Network | 深度神经网络 | CNN:卷积神经网络,RNN:循环神经网络 |
DOA |
Direction of Arrival | 声源定位,找到声源的位置,经常搭配BF使用 | 找到声音方向,比如可以用于机器人根据声源转向,面对说话人 |
DRC |
Dynamic range compression | 动态范围抑制 | 和agc类似,一般用于音频输出,在音量大时,压制音量在某一范围内,音量小时,适当提升音量 |
FAR |
False Alarm Rate | 误唤醒率 | 唤醒测试指标,用于统计外部信号播放24小时内,设备被唤醒次数 |
FRR |
False Rejection Rate | 误识别率 | of missed wake-words / of wake-words spoken |
GSC |
Generalized Sidelobe Cancellatior | 广义旁瓣对消 | 和BF类似,依赖麦克风阵列,以多个固定波束输出结果作为输入,并嘉定对准声源方位为主波束,其他则为参考波束 |
HAL |
Hardware Abstract Laeyer | 硬件抽象层 | 拿Android来说,第三方厂商常常会将各自的算法集成在hal层 |
IAR |
- | 他人误闯 | 用于测试声纹算法鲁棒性 |
IMEI |
International Mobile Equipment Identity | 即通常所说的手机序列号 | 手机“串号”,用于在移动电话网络中识别每一部独立手机等移动通信设备,相当于移动电话身份证 |
IOT |
Internet Of Things | 万物互联 | 也常常指家居设备通过网络互联 |
KG |
Knowledge Graph | 知识图谱 | 显示知识发展进程与结构关系的一系列各种不同图形,用可视化技术描述知识资源及其载体,挖掘,分析,构建,绘制和显示知识及他们之间的相互联系 |
LM |
Language Mode | 语言模型 | 在定制识别时常常涉及不同策略的语言模型 |
N-Gram |
- | 语言模型之一 | 是大词汇连续语音识别中常用的一种语言模型,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model) |
NLP |
Nature Language Processing | 自然语言处理 | “处理”好比控制眼睛、耳朵、舌头的神经,他们将接收的信息转化成大脑可以理解的内部信息 |
NLU |
Nature Language Understanding | 自然语言理解 | “理解”是大脑皮层负责语言理解那部分,数亿脑细胞共同完成的功能。一个人因为其自身家庭背景、受教育程度、接触现实中长期形成的条件反射刺激、特殊的强列刺激、当时的心理状况等因素都会影响和改变“理解”的功能 |
NN |
Neual Network | 神经网络 | 神经网络主要是默认人类脑结构进行的一种代码程序结构的表现,同时是RNN,CNN,DNN的基础。结构上大体上分为三个部分(输入,含隐,输出),各层都有个的讲究,其中,输入层主要是特征处理后的入口,含隐层用来训练相应函数,节点越多,训练出的函数就越复杂,输出层输出相应的预测结果。对于稳态噪声场景,nn有点比较突出 |
NR |
Noise Reduction | 噪声抑制 | 噪声和信号之间的模式差别识别出噪声,信噪比越高,声音之间的差别越大,越容易分离。现在常用的差别包括响度和频率之间的差异,是通话降噪常用算法模块之一 |
MFCC |
Mel-Frequency Cepstral Coefficients | 梅尔平率倒谱系数(音频信号提取特征) | 声道的形态在语音短时功率的包络中显示出来,而MFCCs就是一种准确描述这个包络的一种特征。包含两个关键步骤:转化到梅尔频率,然后进行倒谱分析 |
Oneshot |
One shot | 唤醒和指令一次流畅的说完,不需要唤醒后等待提示音再对话 | 如果没有用oneshot,唤醒后需要等机器反馈“嘟”或“我在”等提示音播报结束再说语音指令 |
PPL |
Perplexity | 混淆度 | 语言模型的衡量指标,ppl越小越好,同时它又是一个相对量 |
Res |
resource | 资源 | 在语音使用时,常常指代算法配置资源等 |
SDS |
Spoken Based Dialog System | 基于语音交互系统 | 类似的还有语音交互界面(SUI,Speech User Interface),直接使用语音和计算机系统交互。类似的还有(GUI,Graph User Interface) |
SER |
Sentence Error Rate | 句错率 | 句错率 = 错误句子数/句总数 |
SNR |
Signal to Noise Ratio | 信噪比 | 有效信号量和噪声干扰的比值,单位dB,常常作为一个衡量麦克风的指标 |
SN |
Serial Number | 序列号 | 指软件注册信息,一般用SN做注册码文件名,数码产品也同样有自己的SN号,常用于设备唯一号用于授权统计 |
THD |
Toal Harmonic Distortion | 总谐波失真 | 声学测试指标,指输出信号比输入信号多出的谐波部分;总谐波失真(THD):<= 1%(1kHz),1kHz频率处谐波失真最小,因此不少产品以该频段作为失真指标,THD指标直接影响AEC消除效果 |
TTS |
Text To Speech | 语音合成 | 将对话需要表达的文字转成声音 |
Turnkey |
turnkey project | 一站式解决方案 | 软硬件打包完整方案 |
VAD |
Voice Activity Detection | 语音端点检测,检测是否有人在说话 | 常用于自动断句和无效输入判断,比如唤醒后几秒内没有说话,会触发vad超时,语音会播报“您没有说话哦” |
VP |
voice Print | 声纹识别 | 根据声音特征,区分发生人,类似指纹功能 |
WER |
Word Error Rate | 字错率 | 字错率 = 识别错误字数/总字数 |
WK |
Wakeup | 语音唤醒 | 固定的指令词来触发语音对话 |
1.4.1关于进一步的说明
具体可以看这里
1.5Android平台
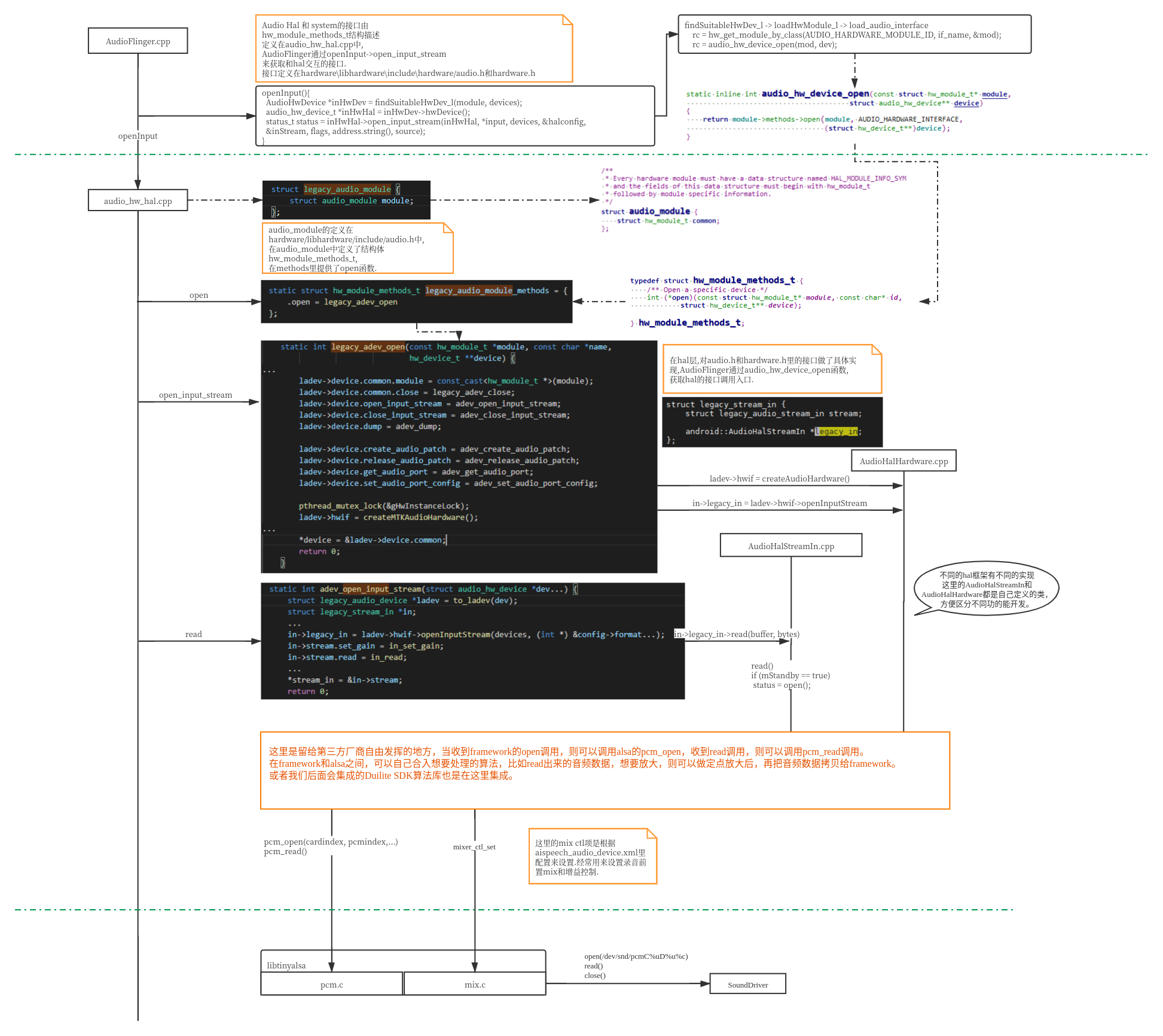
1.5.1Android音频框架简介
整个Android音频框架涉及到的内容非常繁多,因为本章重点是hal层进行算法集成,所以只对上行录音做一个简单介绍。
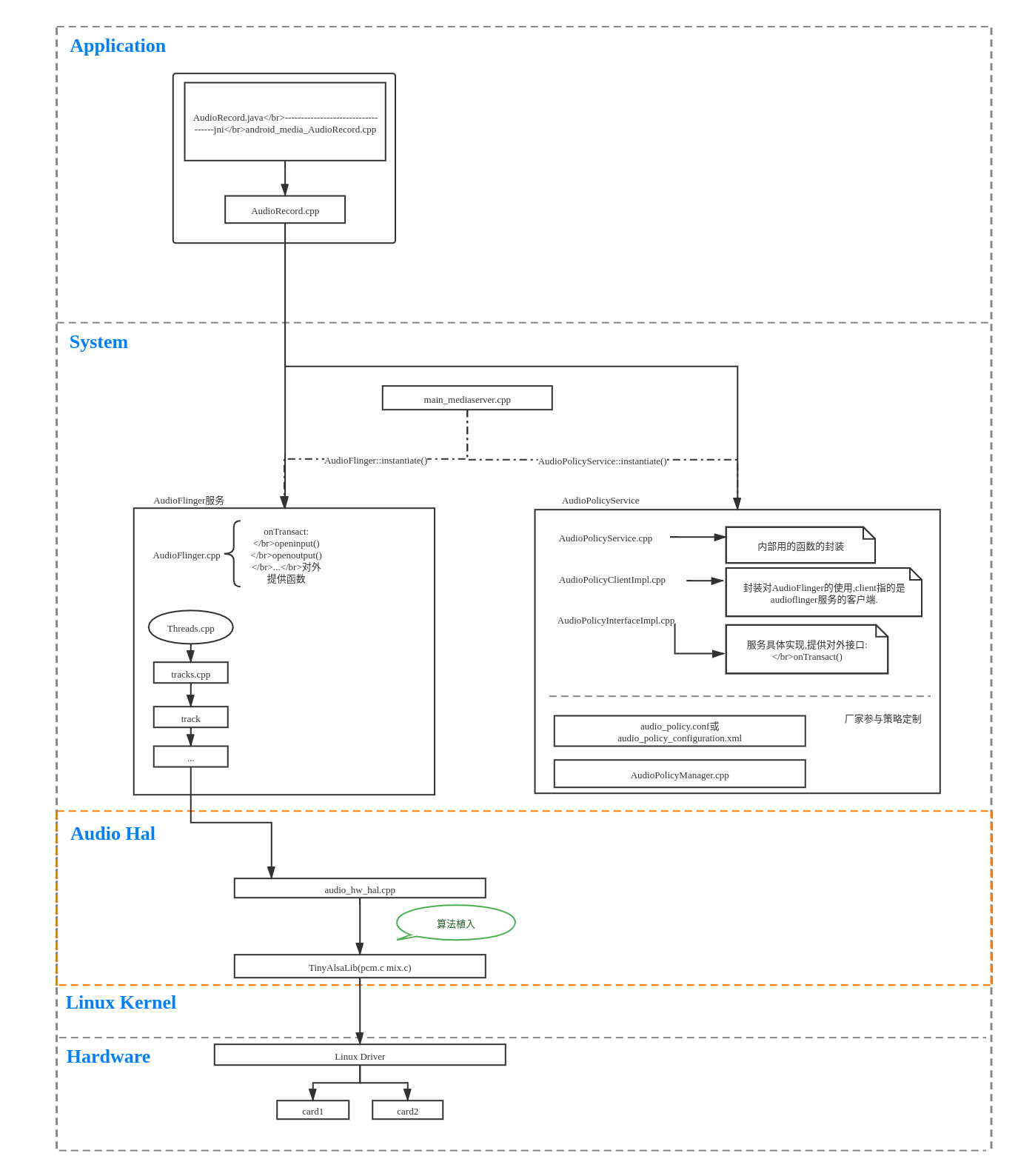
- 从上面框架图可以看出来,整个android系统的模块化和分层思想是非常明显的。这样便于模块集成和不同层的问题排查定位。
- 在application层,只暴露给用户简单的接口,对于录音来说,用户只需要创建AudioRecord,通过AudioRecord来和framework的音频服务通信,用于读取音频数据。
- 整个音频系统最为复杂的都在framework层进行处理了,经常涉及到的主要是两个模块,AudioFlinger和AudioPolicy,分别负责音频操作执行和音频策略选择。怎么理解这两个模块呢?比如录音操作,需要把音频数据从hal层拷贝出来,是一个动作,则由AudioFlinger负责,而是从本机麦克风录音呢?还是从蓝牙耳机录音还是usb声卡录音呢?具体选择哪个设备录音,则有AudioPlicy来决策。
- AudioHal可以看到是一个独立的模块,最终会别编译成一个动态库,由AudioFlinger加载(android 8以后则由专门的vendor server加载,通过binder和framework audioservice进行通信)。它起到一个承上启下的作用,对上实现framework给到的接口,对下调用kernel提供的tinyalsa接口来从驱动获取音频数据。中间有很大的自由度留给第三方厂商进行发挥。
- 在android系统中,在标准linux kernel音频库alsa集成上做了裁剪,提供精简后的tinyalsa版本,主要提供pcm.c用于音频读写和mix.c用于音频通路控制。
1.5.2Android AudioHal接口
- 默认android aosp代码里,Audiohal是空实现的,代码目录在hardware/libhardware(_legacy)/audio/audio_hw.c。源码只将关键的接口和结构体做了实现,而对接tinyalsa的动作则没有实现。
- 因为每家尝试底层驱动千差万别,什么时机open声卡,声卡支持什么样的采样率,采用精度,通道数都是不同的,所以在Hal集成的时候,需要根据底层声卡驱动支持的实际情况来初始化声卡才能正确拿到期望的音频数据。
- 在tinyalsa和audio_hw之间是各个厂商自由发挥的地方,可以根据实际情况来集成想要的算法。
- 在framework调用hal接口adev_open_input_stream的时候,会传入audio_hw_device和audio_config两个参数,device可以用于hal选择audiopolicy决策的音频设备,config则携带了framework期望的录音参数,比如采样率,精度,通道和source,而source可以用于决定hal层采取何种算法类型。source的声明和介绍可以参考MediaRecorder.java里的注释,默认录音可以采用MIC = 1或者 DEFAULT = 0,摄像CAMCORDER = 5,语音识别可以采用VOICE_RECOGNITION = 6,网络通话采用VOICE_COMMUNICATION = 7等。
2相关Audio问题
2.1录音参数检查
在碰到语音问题时,比如无法唤醒,最简单,也最容易出现的问题是录音参数配置错了, 下面列出基于AISpeech Audio Hal适配时不同语音方案的录音参数。
| 录音场景 | AudioSource | SampleRate | ChannelConfig | 对应 Hal 算法 |
|---|---|---|---|---|
| 单麦 | voice_recognition(6) | 16000 Hz | CHANNEL_IN_MONO(1) | AEC |
| 双麦 | voice_recognition(6) | 16000 Hz | CHANNEL_IN_STEREO(2) | AEC |
| 厂测 | voice_recognition(6) | 32000 Hz | CHANNEL_IN_MONO(1) | 无 |
| 四麦 | voice_recognition(6) | 32000 Hz | CHANNEL_IN_STEREO(2) | AEC |
| 六麦 | voice_recognition(6) | 48000 Hz | CHANNEL_IN_STEREO(2) | AEC |
| VOIP通话 | voice_communication(7) | 16000 Hz - 44.1k Hz | CHANNEL_IN_MONO(1) | VOIP |
| 普通录音 | default(0) / mic(1) | 8000 Hz - … | CHANNEL_IN_MONO(1) | AGC |
2.1.1如何查录音参数
Android 默认提供了两个非常有用的命令用于dump framework audioserver的状态:
1adb shell dumpsys media.audio_flingerCopy to clipboardErrorCopied
2adb shell dumpsys media.audio_policyCopy to clipboardErrorCopied
简单讲讲这两个命令,在Android Audio System里, audio flinger担任执行动作的角色,audio policy则担任音频策略的角色,policy的决策如何实现?
依赖/vendor/etc/audio_policy_configuration.xml配置文件,配置文件里决定了不同的声卡由哪个hal库来负责操作,不同声卡的录音参数支持情况等等。
在系统运行时,音频策略决定后,则会统一通过audio flinger来执行,如数打开hal库,下发录音参数,音频数据数据拷贝等等。
有了这个认知后,我们就可以大概知道这里要用到的就是dump audio flinger这个指令,dump后我们找到“Input thread”部分,如下:
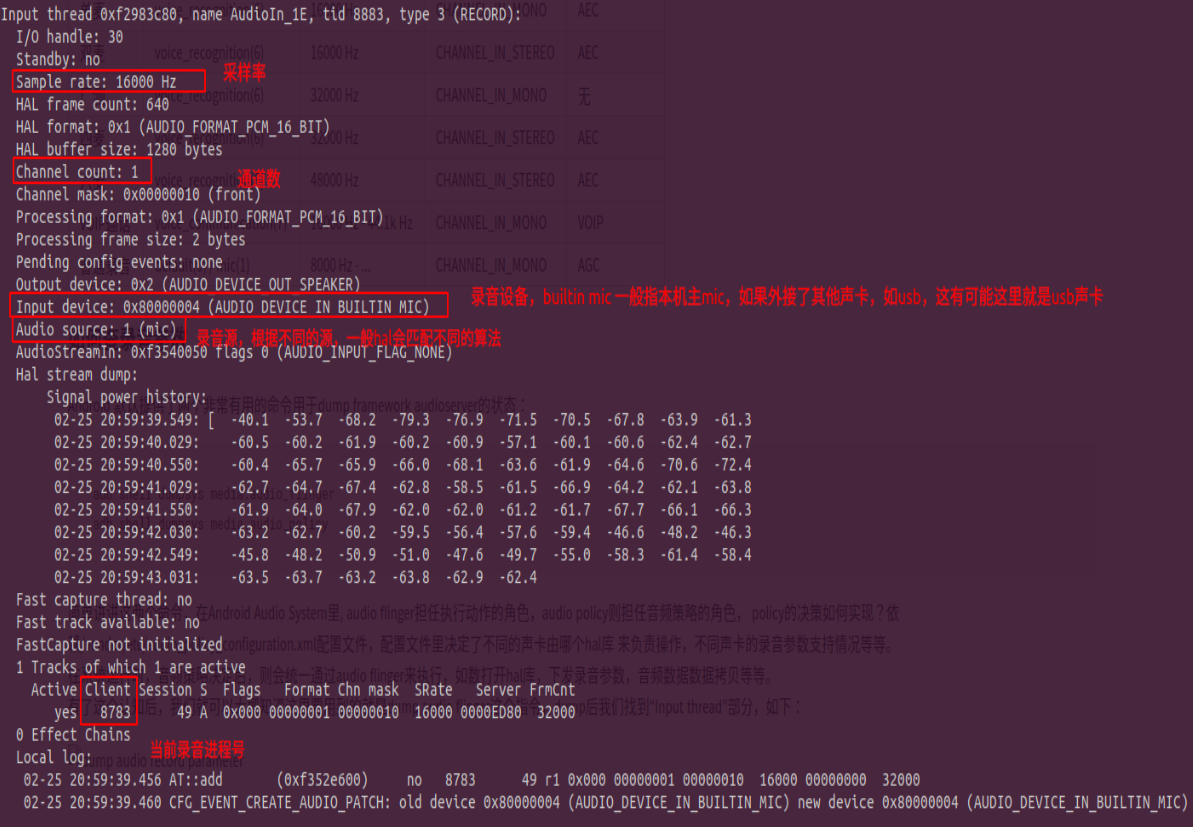
通过上面dump结果,我们可以查到AudioRecord的source,采样率,通道参数,录音设备类型,录音进程号等, 根据这些参数,可以做如下步骤排查:
- 根据录音进程号,判断当前录音进程是否是语音进程,如果不是的话,则说明语音无法使用是录音被占用引起,到底谁占用,参考2.2到底是谁在录音。
- 根据上面提供的语音方案对应录音参数表比对,看录音参数是否和dump的一致,如果不一致,则有可能是AudioRecord初始化时参数设置错误,或者语音sdk配置语音方案出现错误。
- 如果上面两步都符合预期,发现语音还是有问题,这时候就要看音频是否正常,参考2.4如何保存音频如何保存音频)。
2.1.2如何查播放参数
上面说了如何查录音参数,这里再顺便看看如何查播放参数: 和上面两个dump命令一样,在dump audio_flinger的时候,我们主要关注Output thread, 如下:
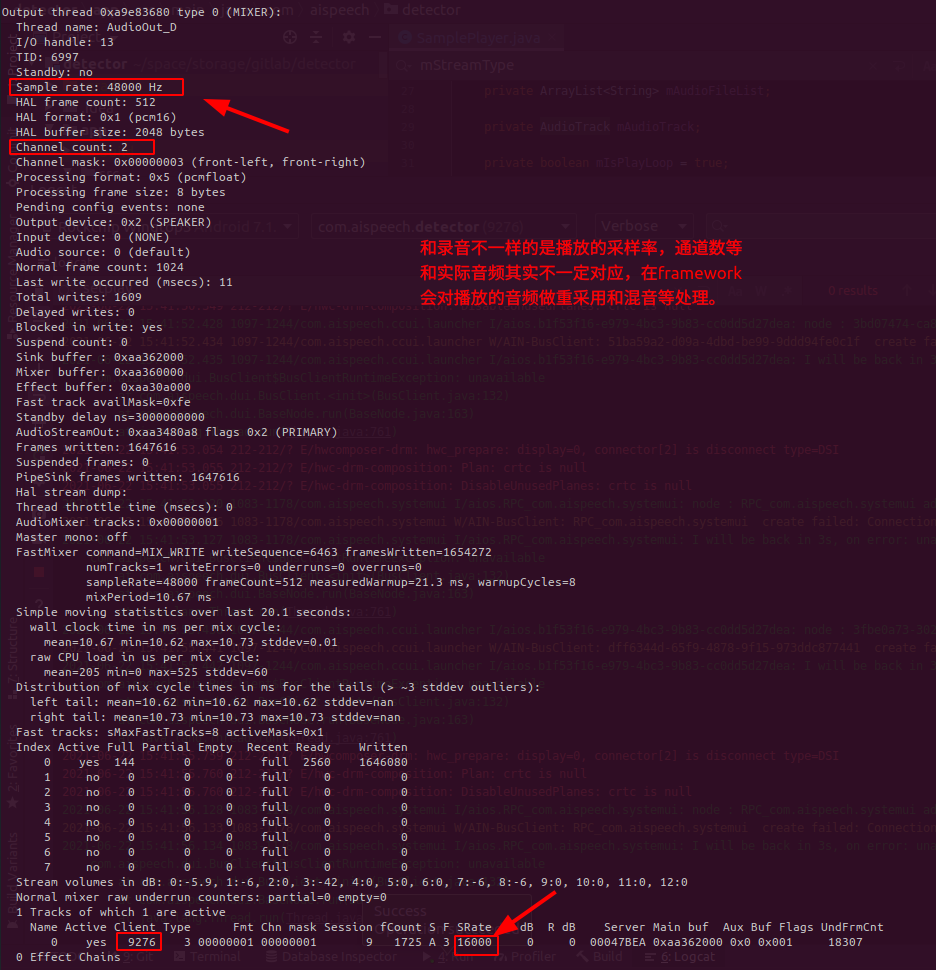
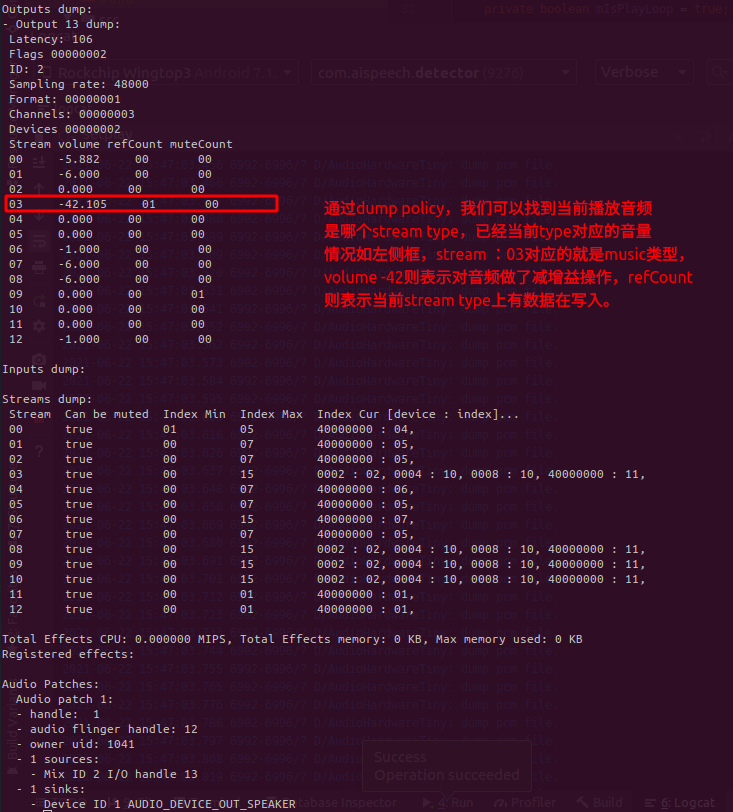
如果我们想知道当前播放是哪个stream type以及对应音量,则可以通过dump audio policy命令来查看,如下
2.2到底是谁在录音
在排查众多语音问题中,我们发现一个非常基础,又非常容易出现的问题就是录音被占用了, 导致语音SDK无法正常拾音而出现无法唤醒或无法识别的情况,但是我却不知道是谁在背后捣蛋。
-
抓log看 在Android10以前,原生系统对多app同时录音并不支持,这会导致第一个app在录音时, 再启动一个AudioRecord实例录音会出现报错,可以通过logcat抓取日志后分析(这里以Android8.1为例), 过滤audio看是否有already started和status -38的打印:
1W/APM_AudioPolicyManager: startInput(38) failed: other input 30 already started 2E/AudioRecord: start() status -38 3E/MediaRecorder: start failed: -38 -
通过dump命令看是录音进程归属
1adb shell dumpsys media.audio_flinger在dump结果里,我们找是否存在“Input thread”的部分,如下图:
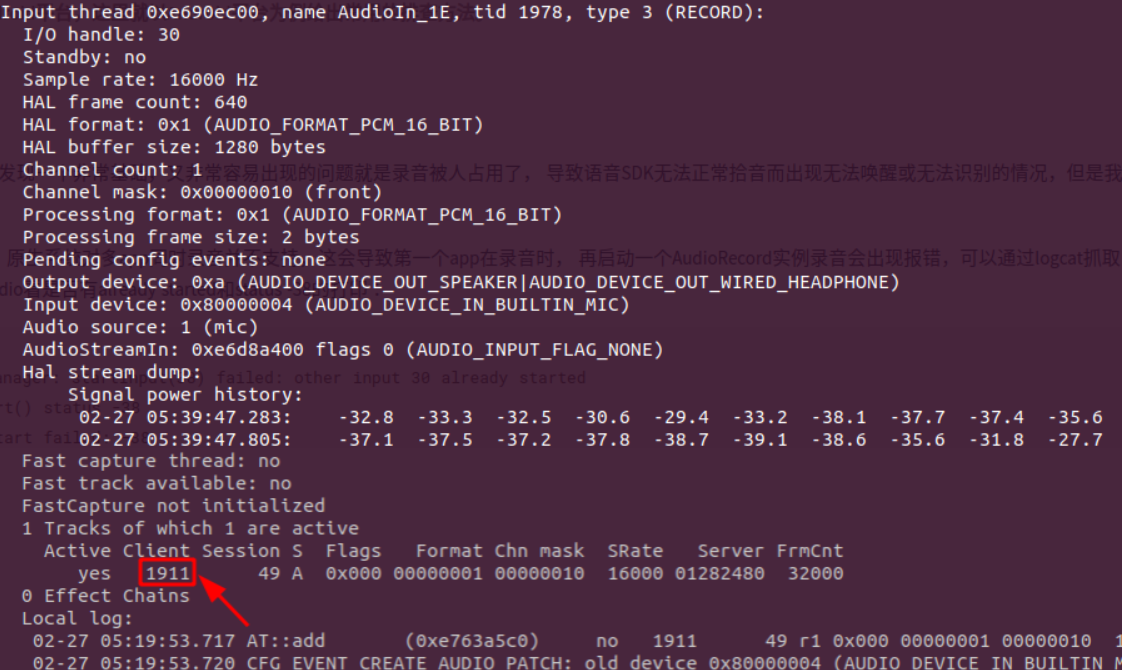
利用Client找到的录音进程号,通过ps命令来确认进程包名(android8以下不需要加-A参数),如果不是本应用录音的包名, 说明是其他app在录音,如果和本应用同包名,可能是之前录音线程没有正常关闭导致,可以杀掉进程后再尝试。

-
其他情况
当然,还有一种极端情况,就是有进程跳过了Android的framework层,直接通过文件节点在录音,这也会导致录音失败, 但是在dump结果中却没有“Input thread”部分的打印。那该如何排查呢?首先我们写一个脚本用于确认这时候的确有人在录音, 同时通过一些linux的命令即可确认,如下:
1dir=/proc/asound/card* 2 3for file in $dir/*; do 4 if [[ $file == *c ]]; then 5 card="$file""/sub0/hw_params"; 6 echo $card; 7 cat $card; 8 fi 9done将如上shell命令保存到文件,例如found_opendev.sh,然后将其push到root后的设备的/data目录,并赋予执行权限。
1adb push found_opendev.sh /data 2adb shell 3chmod 777 /data/found_opendev.sh 4./found_opendev.sh如果发现hw_params有录音参数,则说明的确有进程在录音。 根据打开的声卡,看status里的owner_pid来确认是哪个进程在录音。
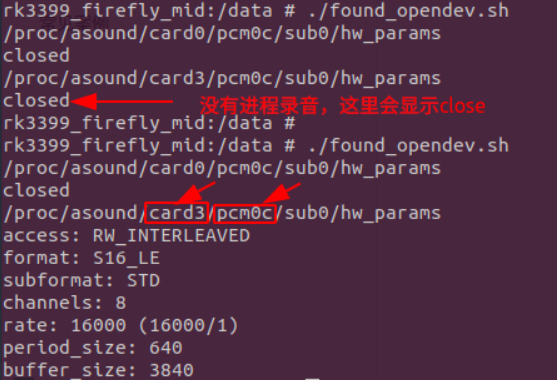
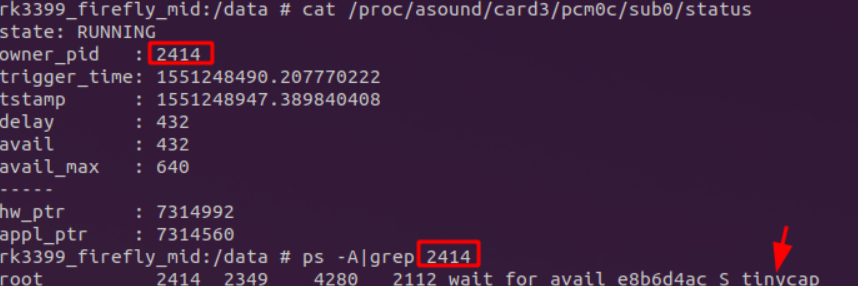
2.3录音冲突
在Android平台,默认情况不支持多个APP同时录音,如果语音APP启动了唤醒功能在后台录音,其他应用想在这时候启动录音大部分情况是会失败。 这里举最常见的一个例子带大家一起分析问题原因以及如何处理:
2.3.1问题现象
语音启动后,通话没声音。
2.3.2问题原因
在Android平台的framework的AudioPolicyManager::startInput里有判断,如果已经有record在录音,后面尝试启动录音时会被认为是invalid操作,被直接return了。(下面是android11的代码)
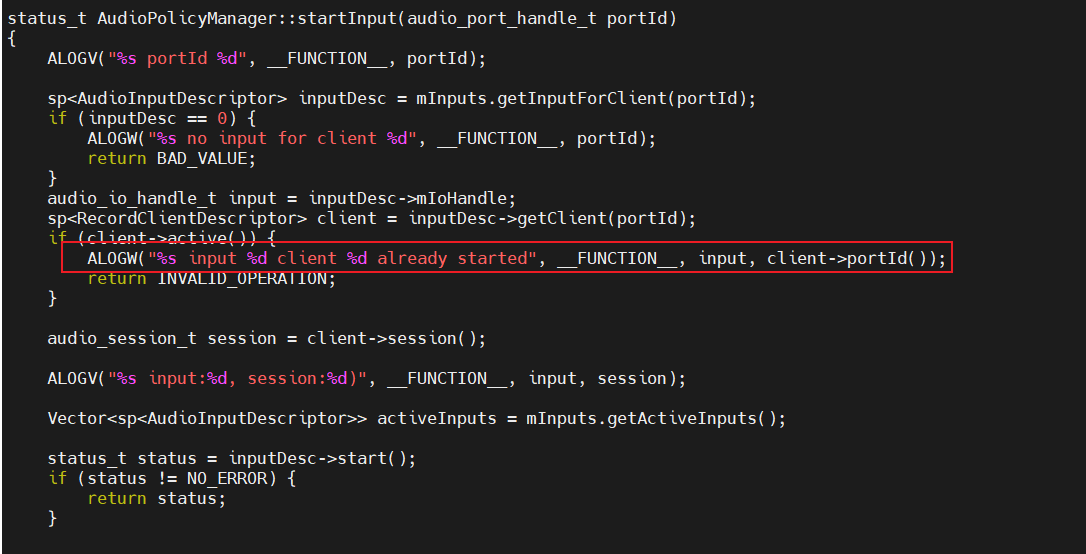
2.3.3处理方案
| 方案 | 操作说明 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| APP状态同步方案 | 遵循Android设计,同一时间只允许一个APP录音,当语音在录音时需要通话,则在通话接通前发命令给语音APP(如广播等),语音APP关闭录音后,再通知通话APP启动录音。通话APP结束通话后释放录音,再发消息给语音APP,语音APP重新启动录音。 | 无需系统层修改,应用层即可处理 | 应用层操作繁琐,一旦消息状态同步异常,容易导致无法唤醒或通话没声音问题。在产品需求方面,没办法在源头解决同时录音需求 | 系统无法修改或者没有集成AISpeechAudioHal时使用 |
| l录音复用方案 | 1,在hal里默认对录音复用做了支持; 2,系统framework的AudiopolicyManager修改 | 源头上处理了多APP同时录音问题,录音异常bug减少 | 对系统有一定植入性 | framework允许修改。 通话APP等录音APP无法和语音APP通信同步状态 |
第二种方式修改如下
2.3.3.1低版本
根据报错的地方 , 找到对应的报错的文件和对应的函数. 在android低版本时报错会在/hardware/libhardware_legacy/audio/AudioPolicyManagerBase.cpp中的startInput()函数中. 将1报错的地方的return注释掉, 保证startInput可以正常调用到hal层
1///hardware/libhardware_legacy/audio/AudioPolicyManagerBase.cpp#startInput
2status_t AudioPolicyManagerBase::startInput(audio_io_handle_t input)
3 stopInput(activeInput);
4 releaseInput(activeInput);
5 } else {
6+ #if 0 /* porting aispeech audio hal, support multi inputs at the same time */
7 ALOGW("startInput() input %d failed: other input already started..", input);
8 return INVALID_OPERATION;
9+ #endif
10 }
11 }
12 }
2.3.3.2高版本
如果是高版本的android版本, 则这个报错可能在frameworks/av/services/audiopolicy/managerdefault/AudioPolicyManager.cpp中
1//frameworks/av/services/audiopolicy/managerdefault/AudioPolicyManager.cpp
2status_t AudioPolicyManager::startInput(audio_io_handle_t input, audio_session_t session)
3{
4ALOGV("startInput() input %d", input);
5 stopInput(activeInput);
6 releaseInput(activeInput);
7 } else {
8+ #if 0 /* porting aispeech audio hal, support multi inputs at the same time */
9 ALOGE("startInput(%d) failed: other input %d already started", input, activeInput);
10 return INVALID_OPERATION;
11+ #endif
12 }
13 }
14 }
15
具体报错的地方请根据自身代码, 参考上面示例 , 将对应的地方注释掉. 保证多个app同时录音时 , 不会在framework层被return掉。
2.3.3.3其他
android10上, AudioPolicy新增了对app状态的管理
当多个app同时录音时, 会根据app的状态选择对优先级低的app录音数据做silence处理.
导致后台app录取到的音频数据是0, 简单的处理方法就是把audioflinger中的silence处理注释掉
1diff --git a/audioflinger/AudioFlinger.cpp b/audioflinger/AudioFlinger.cpp
2index 47dd1a7..61b5054 100755
3--- a/audioflinger/AudioFlinger.cpp
4+++ b/audioflinger/AudioFlinger.cpp
5@@ -1175,7 +1175,8 @@ bool AudioFlinger::getMicMute() const
6void AudioFlinger::setRecordSilenced(uid_t uid, bool silenced)
7{
8MTK_ALOGD("AudioFlinger::setRecordSilenced(uid:%d, silenced:%d)", uid, silenced);
9-
10+//aispeech:no need silence,if you want multi app record in same time. _2020.8.15
11+#if 0
12AutoMutex lock(mLock);
13for (size_t i = 0; i < mRecordThreads.size(); i++) {
14mRecordThreads[i]->setRecordSilenced(uid, silenced);
15@@ -1183,6 +1184,7 @@ void AudioFlinger::setRecordSilenced(uid_t uid, bool silenced)
16for (size_t i = 0; i < mMmapThreads.size(); i++) {
17mMmapThreads[i]->setRecordSilenced(uid, silenced);
18}
19+#endif
20}
2.4如何保存音频
不管多么复杂的软件,都有一个分层的思想,所以我们分析保存音频也类似,出现问题时,我们需要抓取各个层的音频来分析, 通过对比,可以快速定位问题在哪个层面出现。(以Android设备为例)
| 分层 | 调试接口和工具 |
|---|---|
| Application | AudioRecord |
| Framework | dumpsys media.audio_flinger/audio_policy |
| Audio Hal | Detect.apk: base on aispeech audio hal patches |
| Kernel | tinyalsa tools:tinycap tinymix |
| Hardware | logic analyzer/multimeter |
如果对语音的问题和现象不是很熟悉的话,通常建议是从底层往上查:
- 硬件层:通常有硬件工程师负责,通过仿真排查电路问题或者用万用表,示波器等工具测量电路信号是否符合预期。
- 内核驱动层: 通常采用tinymix配合tinycap录音来测试,如果tinycap录音数据异常,则说明底层驱动有问题。参考3.1tinyalsa
- audio hal: 通常有芯片厂商提供debug接口原生芯片Debug接口
- framework: 目前没有音频保存的接口,但是有dump audio flinger 和 dump audio policy两个指令来将音频系统的状态参数打印处理。
- application: 通常采用AudioRecord或者MediaRecord系统接口来读取数据,保存音频文件分析。
注意: 在hal音频保存开关打开后,有时候没有音频保存,一般有三种可能:
- 没有app在录音;
- 录音被其他app占用了,导致保存的音频不是想要的;
- 系统权限问题,可以通过getenforce命令查看,如果是Enforcing,则需要手动关掉再尝试保存,关掉命令:setenfoce 0 。
2.5如何分析音频
在分析音频前,我们先来看看什么是PCM格式音频
前面介绍了如何对音频进行采样, 采样的原始音频数据大部分是以PCM(Pulse Code Modulation,脉冲编码调制)格式保存的,所以我们用audacity分析音频时,也以分析原始音频为主。
音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准数字音频数据。
描述PCM数据的6个参数:
- Sample Rate : 采样频率。8kHz(电话)、44.1kHz(CD)、48kHz(DVD)。
- Sample Size : 量化位数。通常该值为16-bit。
- Number of Channels : 通道个数。早期音频格式主要是两个左右通道,但是随着多麦阵列出现,8通道或更多通道音频都有出现。
- Sign : 表示样本数据是否是有符号位,比如用一字节表示的样本数据,有符号的话表示范围为-128 ~ 127,无符号是0 ~ 255。一般是有符号位。
- Byte Ordering : 字节序。字节序是little-endian还是big-endian。通常是little-endian。
- Integer Or Floating Point : 整形或浮点型。大多数格式的PCM样本数据使用整形表示,而在一些对精度要求高的应用方面,使用浮点类型表示PCM样本数据。
1)数据格式:
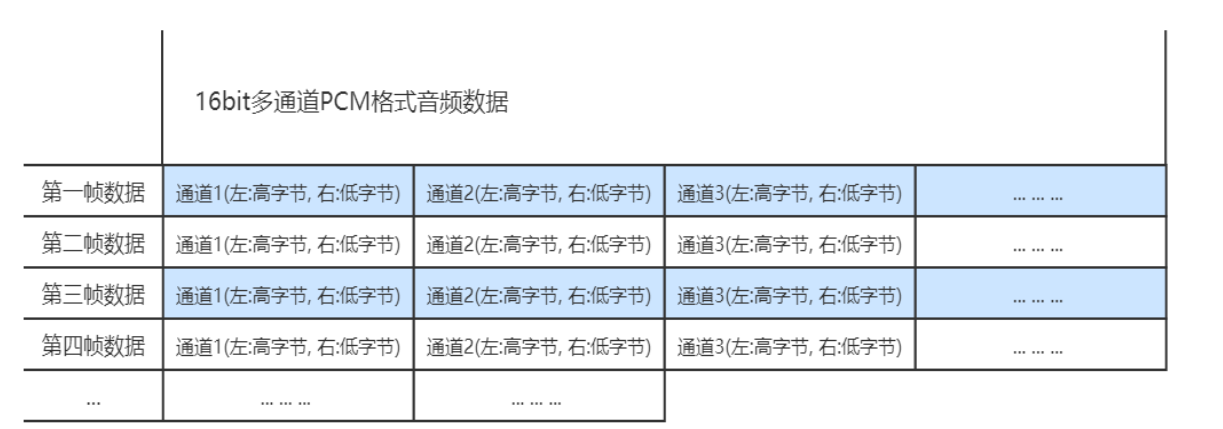
如果是单声道的音频文件,采样数据按时间的先后顺序依次存入(有的时候也会采用LRLRLR方式存储,只是另一个声道的数据为0), 如果是多声道的话就按照C1C2C3C4….C1C2C3C4….的方式存储,存储的时候与字节序有关。little-endian模式如下图所示:
2)字节序
谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86系列CPU。PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。
3)big endian and little endian
big endian是指低地址存放最高有效字节(MSB,Most Significant Bit),而little endian则是低地址存放最低有效字节(LSB,Least Significant Bit)。
下面用图像加以说明。比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
Big Endian
低地址 高地址
—————————————————————————–> | 12 | 34 | 56 | 78 |
Little Endian
低地址 高地址 —————————————————————————–> | 78 | 56 | 34 | 12 |
所有网络协议都是采用big endian的方式来传输数据的。所以也把big endian方式称之为网络字节序。
2.5.1wav和pcm格式音频有什么区别?
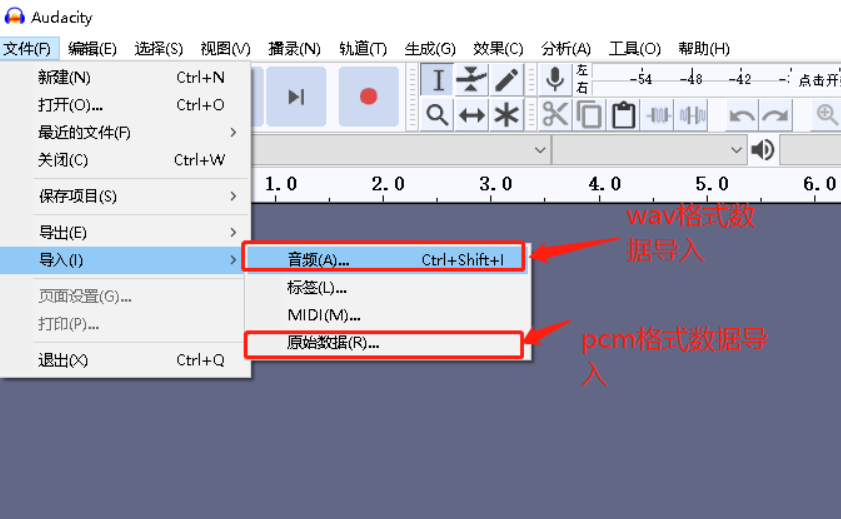
区别在于wav格式音频是pcm格式音频的基础上,添加了一个44字节的文件头, 实际音频数据存储是一致的,所以我们导入音频的时候要注意区分。
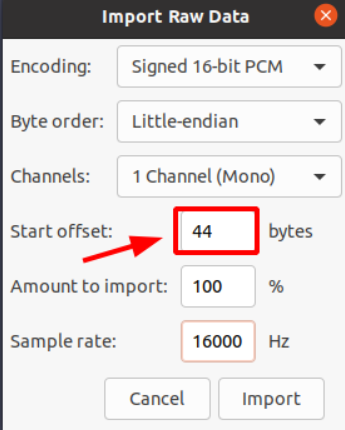
如果以“原始数据”方式导入wav格式数据,则需要在导入参数里在起始位置偏移掉44个字节,否则会出现通道错乱情况。
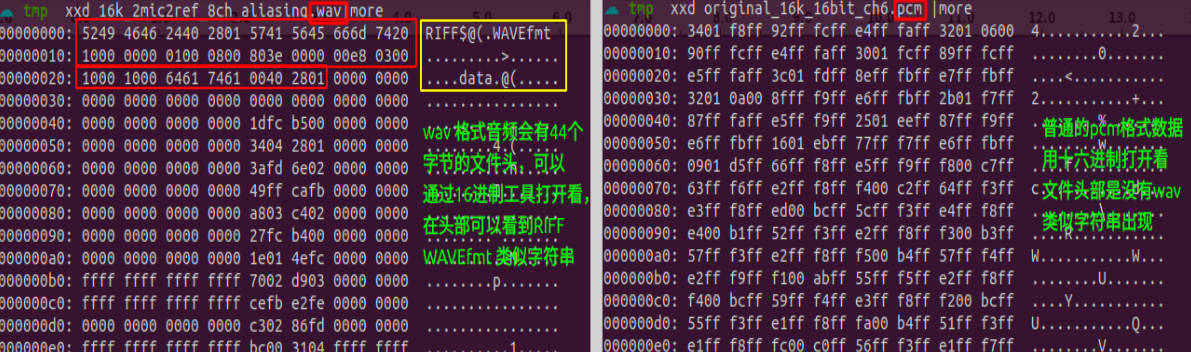
在实际工作中,我们常常碰到音频命名错乱的问题,如pcm格式音频命名成wav结尾了,wav格式的反而命名成pcm格式。 为了避免这些不专业的命名扰乱我们分析问题,有没有一个简单的方式来鉴别呢?这里提供一个linux常用命令:file工具来分析。
1file ok_4mic2ref.pcm
2ok_4mic2ref.pcm: data
3file ch4_2.wav
4ch4_2.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, 4 channels 16000 Hz
2.5.2音频分析需要几步
从来没有分析过音频的人来说,对于一个音频是否正常,不知道如何下手,觉得这是一个无比困难的问题。 就像要把大象装进冰箱一样,不知道要怎么做。🤭 实际上你只需要三步:1、把冰箱门打开 2、把大象放进去 3、把冰箱门关上。
分析音频也一样,分三步:
- 导入音频。
- 用耳朵听音频是否正常,转换频谱观察是否正常。
- 对比问题音频异常音频和硬件验收指标, 看当前音频是否属于异常音频或者达不到验收指标。
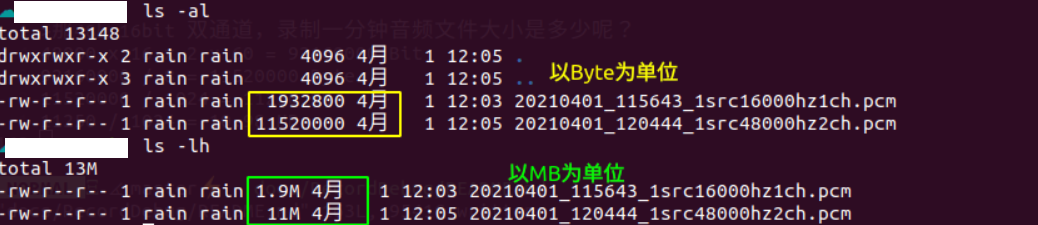
2.5.3音频文件大小对比
观察音频数据大小是否符合预期,也是我们常用的一个分析音频的手段。
计算公式如下,如果保存文件大小异常,则要排查是否丢数据了或者采样率,时钟配置。如果音频文件都是0, 则要考虑保存文件是否遇到权限问题,或者更底层的问题,一般出现这种情况,从log中都是可以看到明显异常。
1公式: 采样率x采用精度x通道数x录制时间(单位秒) = 文件大小(Bit)
举例:
1#16k 16bit 单通道,录制一分钟音频文件大小是多少?
216000 x 16 x 1 x 60 = 15360000 Bit
但是实际我们使用的时候,常常不是用Bit为单位,而是Byte, KB,MB,GB 换算规则如下:
11 Byte = 8 Bits
21 KB = 1024 Bytes
31 MB = 1024 KB
41 GB = 1024 MB
所以将上述音频换算成常见单位,如下:
115360000 / 8 = 1920000 Byte
21920000 / 1024 = 1875 KB
31875 / 1024 = 1.83 MB
那48k 16bit 双通道,录制一分钟音频文件大小是多少呢?
148000 x 16 x 2 x 60 = 92160000 Bit
292160000 / 8 = 11520000 Byte
311520000 / 1024 = 11250 KB
411250 / 1024 = 10.98 MB
下面截图是实际录音测试的音频,基本符合我们理论计算值,所以可以大致判断录音保存文件大小是正确的。
2.6丢数据音频
如果扫频波数据丢失,正常的频谱图会出现一条明显竖线
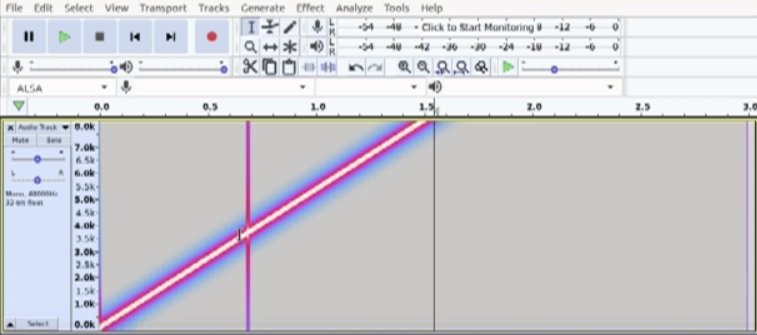
- 什么原因导致丢数据呢?
- 硬件传输不稳定,外挂设备容易出现。
- 录音参数不合理,例如设置给alsa的采样率,采用精度,period和period_count等和底层驱动不匹配。
- app层录音线程阻塞,导致底层音频数据溢出。
- 如何解决?
- 保证外挂设备和主机端传输稳定。避免出现断连情况,同时在收发数据端都预留一定的缓冲区,减少时钟偏差导致的数据溢出。
- 和硬件,驱动沟通,下发正确的录音参数。
- 在app层读数据的录音线程不要阻塞,提高录音线程的优先级,同时在Audio Hal层添加一定的缓冲buffer,给应用层一些处理时间。
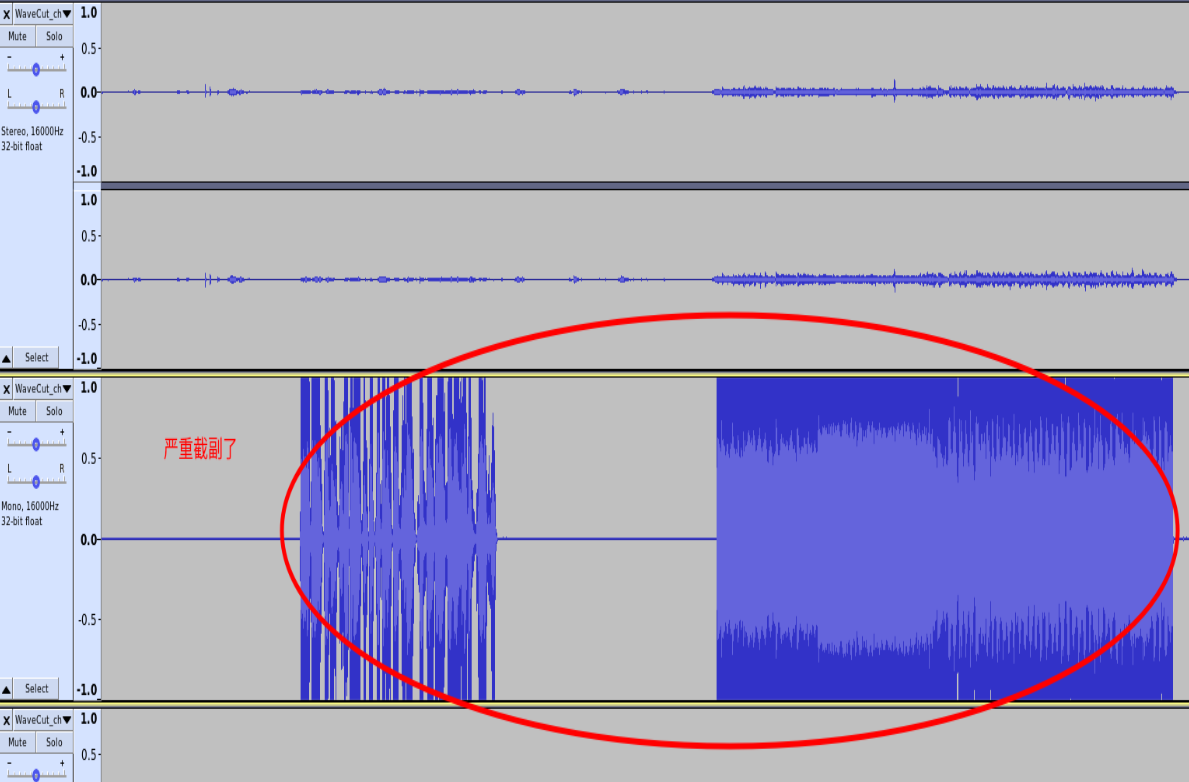
2.7截幅音频
这类音频出现的频率最高,也最好处理。 截幅和削波通常是同时存在的,但是也有削波不截幅的情况:
- 引发问题:
- 播放音乐时唤醒率低。
- 唤醒后识别出现首字错误或识别结果有播报语情况。
- tts播报时打断效果不佳。
- 如何解决: 一般出现该问题都是增益配置不正确引起,可以通过调节增益接口来将音频幅度调节到一个合理范围。 部分参考回路有时候增益调到0也出现截幅,这时候需要修改硬件,加大分压电阻, 同理,如果增益调到最大,参考回路的幅度也还是偏小,则相应的减少分压电阻。
偏大偏小都是基于音频验收标准文档为基准。 如下图是参考回路严重截幅的情况:
2.8音频通道确认
- 音频通道怎么确认?
- 线麦阵列遵守从左到右,环形麦遵守逆时针顺序排列。
- 一般用手指头依次敲击(避免指甲敲击,产生过多震动),或者用吸管对准mic孔按顺序吹气,将录音音频导出分析验证。
- 注意录音数据如果是wav格式音频,导入时需要偏移44字节,如果是pcm格式数据,则不需要偏移。
2.9底噪过大
底噪测试分为两部分:
- mic底噪测试,最好是在静音室测试,避免外界噪声干扰。
- 参考回路测试,则对外界环境没有要求,根据需求播放指定音频即可。
2.10恒频干扰音频
测试恒频时,建议在安静的环境测试,避免外接噪声干扰。
- 如何解决 恒频干扰问题可从电源处入手,查看供电是否稳定、干净,更换成 LDO 给 MIC 阵列供电等方式解决问题;或者检查 MIC 信号走线是否与其他电信号存在 串扰可能,常见串扰包括 LED,触控 IC 等。
异常音频用audacity导入后转换成频谱图后看,是可以看到固定频段会有一条直线,如下图,在6.3KHz的地方存在恒频。

2.11 混叠音频
先来看两组混叠和没有混叠的音频,如下
混叠音频
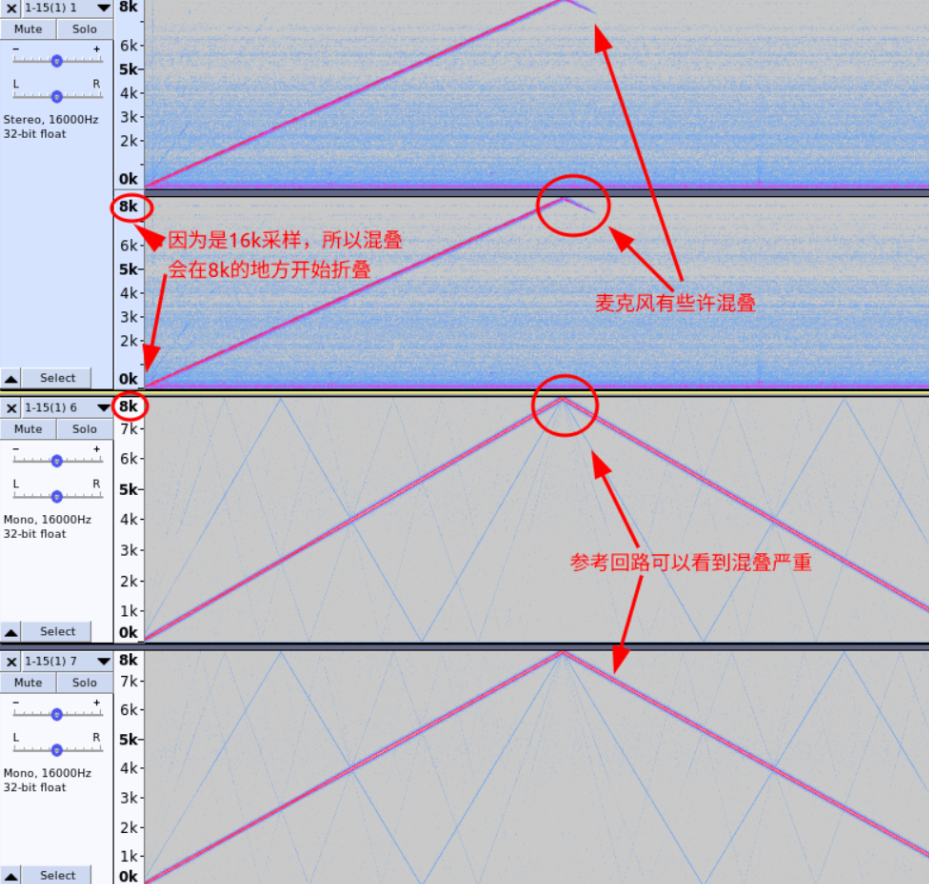
无混叠音频
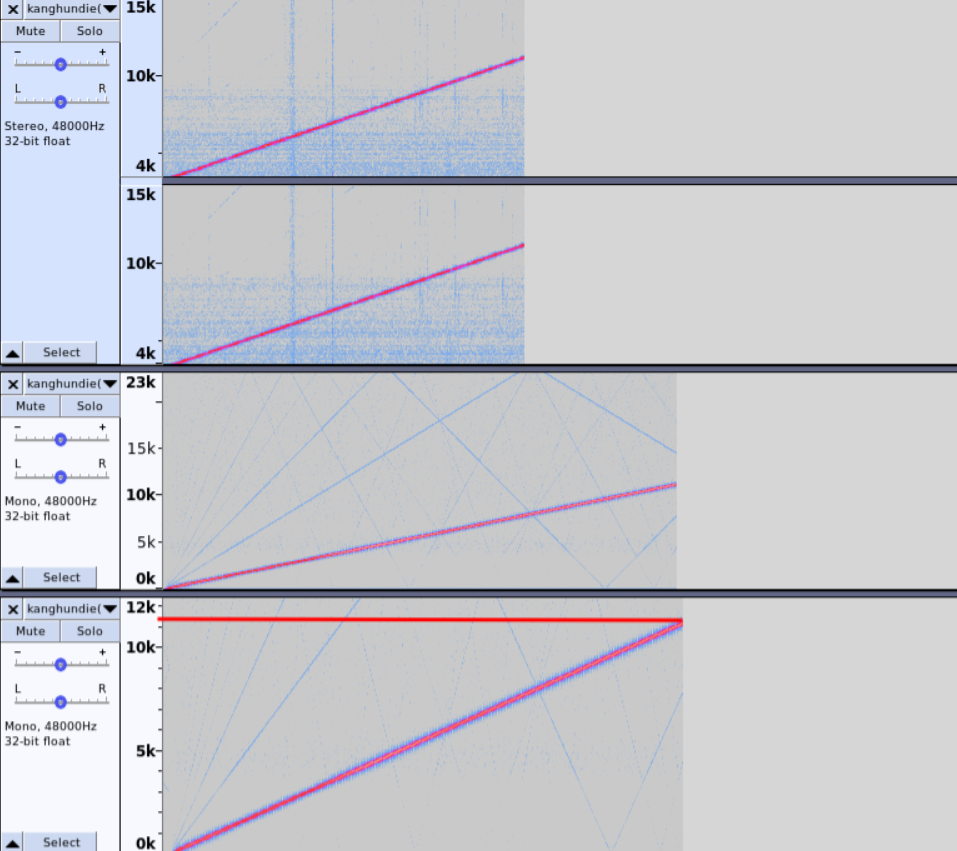
1.什么是混叠?
需要被采样的数字信号频率高于采样频率1/2的频率,高出来的频率将被重采样成低于采样率的1/2频 率的信号,高频信号被低频信号代替,两种波形完全重叠在一起,形成严重失真,这种频谱的重叠导致 的失真称为混叠.
2.如何消除混叠?
1a. 提高采样频率:提高到被采样频率的2倍以上,但不可能将采样频率提高到无限大, 通过提高采样频率避免混叠是有限制的。
2
3b. 采用抗混叠滤波器:
4在采样频率一定的,通过低通滤波器滤掉高于1/2的频率成分,低通滤波器的信号则可避免出现频率混叠.
5若不能确保信号的最高频率小于采样频率的1/2,就必须通过低通滤波器限制输入信号的频率,过滤掉高
6于采样率1/2的频率。
7
8c. 滤波器说明
9低通滤波器:通低频,阻高频.
10高通滤波器:通高频,阻低频.
香农采样定理,又称奈奎斯特采样定理,是信息论,特别是通讯与信号处理学科中的一个重要基本结论。1924年奈奎斯特(Nyquist)就推导出在理想低通信道的最高大码元传输速率的公式:理想低通信道的最高大码元传输速率B=2W,信息传输速率C=B*log2N 。(其中W是理想低通信道的带宽,N是电平强度)
1fs > 2* fN
时域采样理论
如果我们将采样定理应用于频率为 f SIGNAL的正弦波,如果我们想要实现完美重建,就必须在 f SAMPLE ≥ 2f SIGNAL处对波形进行采样。换句话说,我们每个正弦周期至少需要两个样本。让我们首先尝试通过在时域中思考来理解这个要求。
在下图中,正弦波的采样频率远高于信号频率。
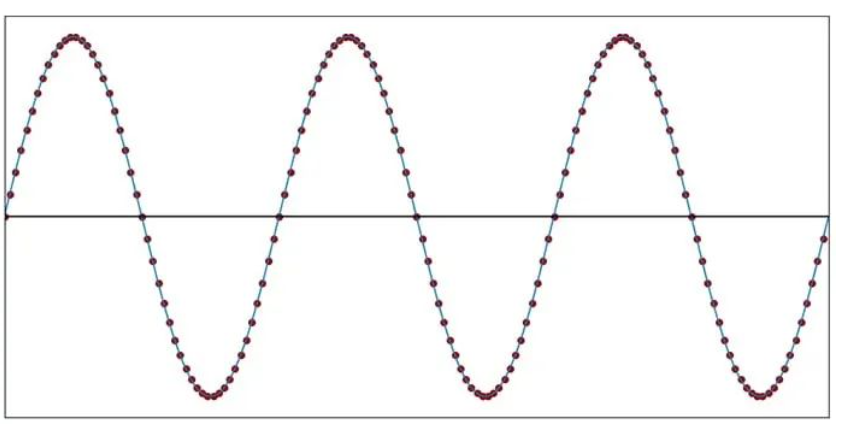
每个圆圈代表一个采样时刻,即测量模拟电压并将其转换为数字的精确时刻。
为了更好地可视化此采样过程为我们提供的内容,我们可以绘制样本值,然后用直线将它们连接起来。下图中显示的直线近似看起来与原始信号完全一样:采样频率相对于信号频率非常高,因此线段与相应的曲线正弦曲线段没有明显不同。
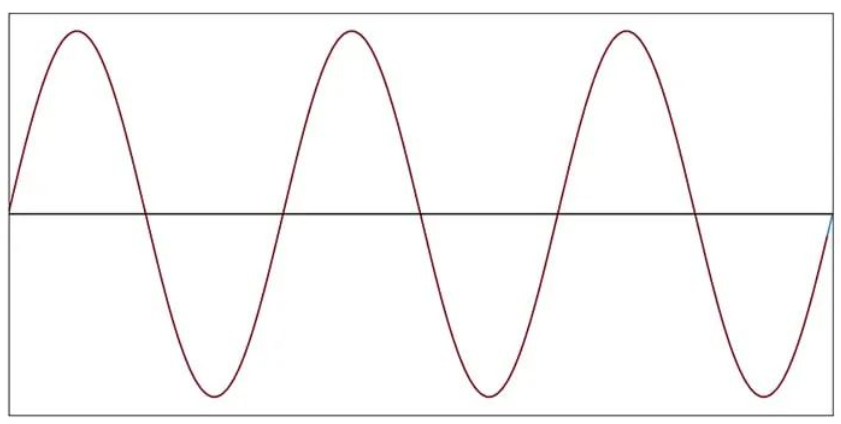
当我们降低采样频率时,直线近似的外观与原来的不同。
每个周期 20 个样本(f样本= 20f信号)
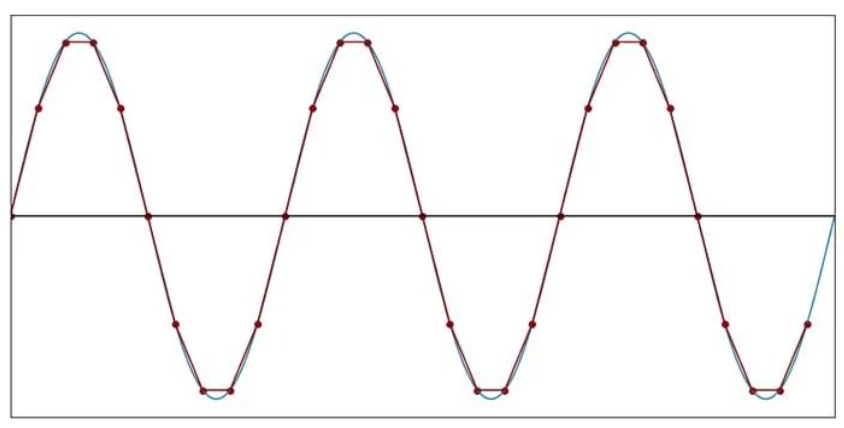
每个周期 10 个样本(f样本= 10f信号)
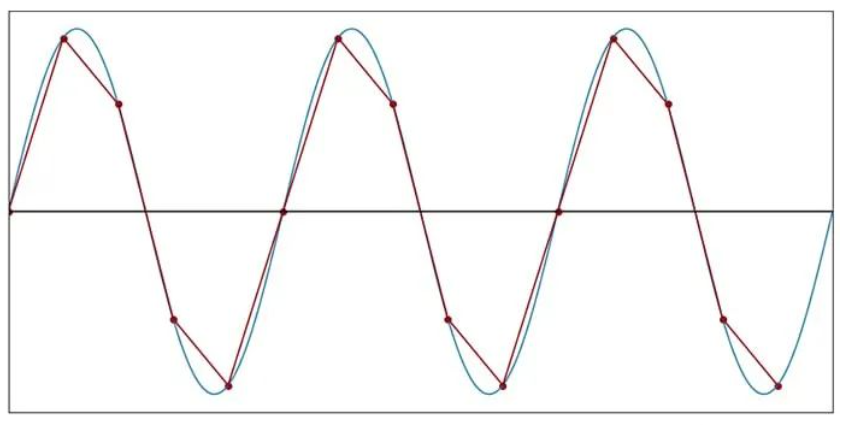
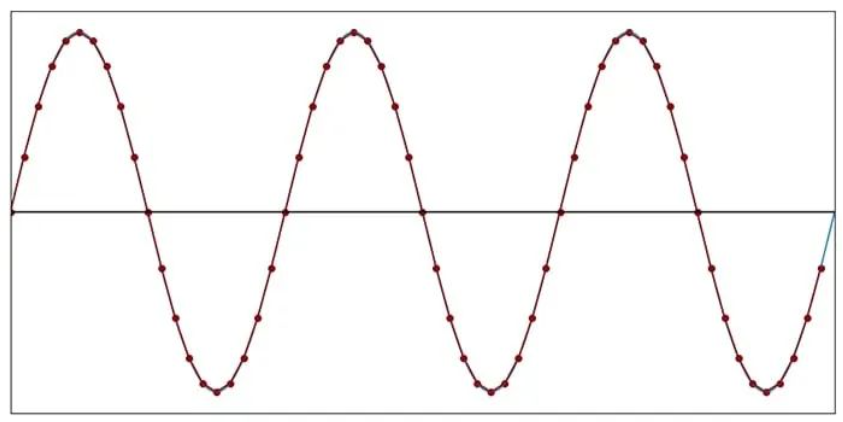
在 fSAMPLE= 5fSIGNAL时,离散时间波形不再是连续时间波形的令人满意的表示。但是请注意,我们仍然可以清楚地识别离散时间波形的频率。信号的循环性质并没有丢失。
阈值:每个周期两个样本
当我们将每个周期的样本数减少到五个以下时,采样产生的数据点将继续保留模拟信号的循环性质。然而,最终我们达到了频率信息被破坏的程度。考虑以下情节:
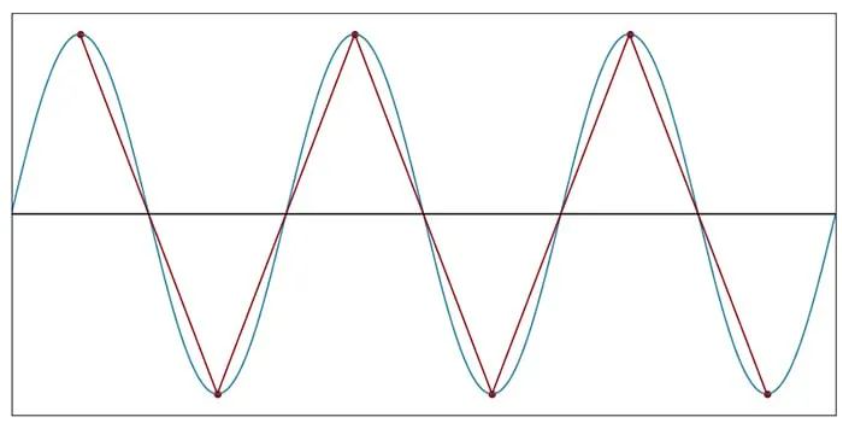
每个周期 2 个样本(f样本= 2f信号)
当 fSAMPLE= 2fSIGNAL时,正弦曲线形状完全消失。尽管如此,采样数据点产生的三角波并没有改变正弦波的基本周期性。三角波的频率与原始信号的频率相同。
但是,一旦我们将采样频率降低到每个周期少于两个样本的程度,就无法再做出这种说法。因此,对于原始波形中的最高频率,每个周期两个样本是混合信号系统中至关重要的阈值,相应的采样频率称为奈奎斯特速率:
如果我们以低于奈奎斯特速率的频率对模拟信号进行采样,我们将无法完美地重建原始信号。
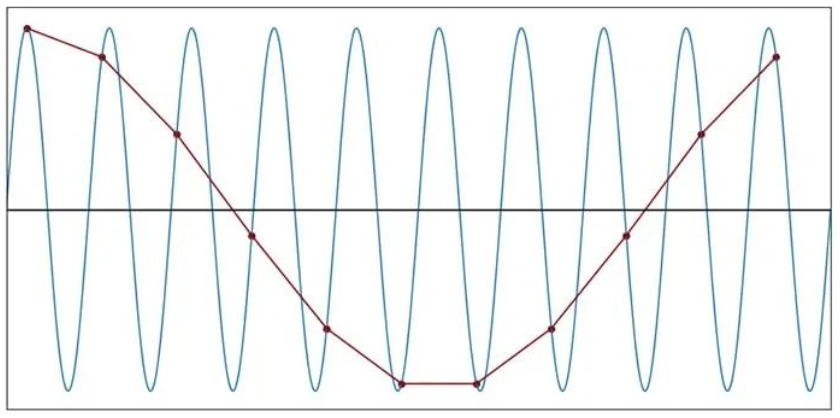
每个周期 1.1 个样本(f样本= 1.1f信号)
如果您对正弦曲线一无所知并使用以 1.1f SIGNAL采样产生的离散时间波形进行分析,您将对原始信号的频率形成严重错误的想法。此外,如果您拥有的只是离散数据,则不可能知道频率特性已被破坏。采样创建了原始信号中不存在的新频率,但您不知道该频率不存在。
底线是:当我们以低于奈奎斯特速率的频率进行采样时,信息将永久丢失,并且无法完美地重建原始信号。
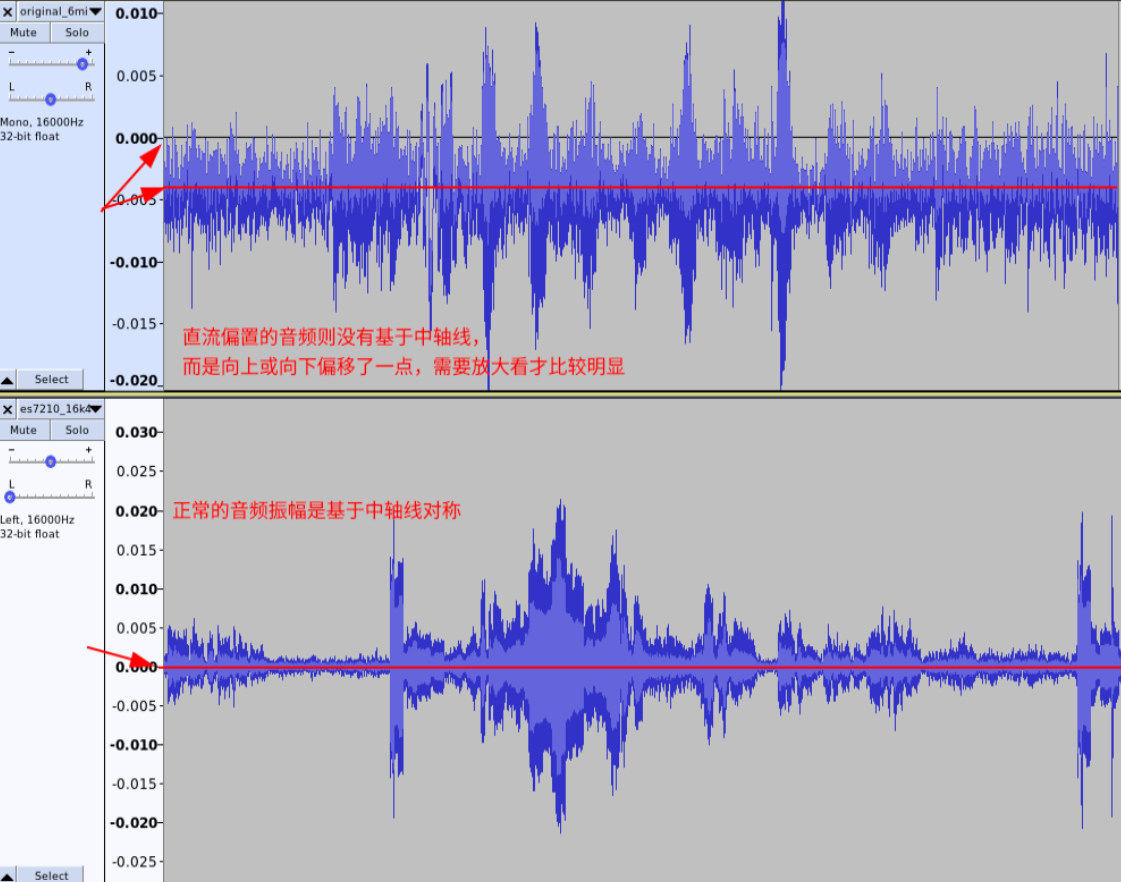
2.12直流偏置过大
直流偏置过大,容易出现截幅等情况,也会影响增益配置等问题。
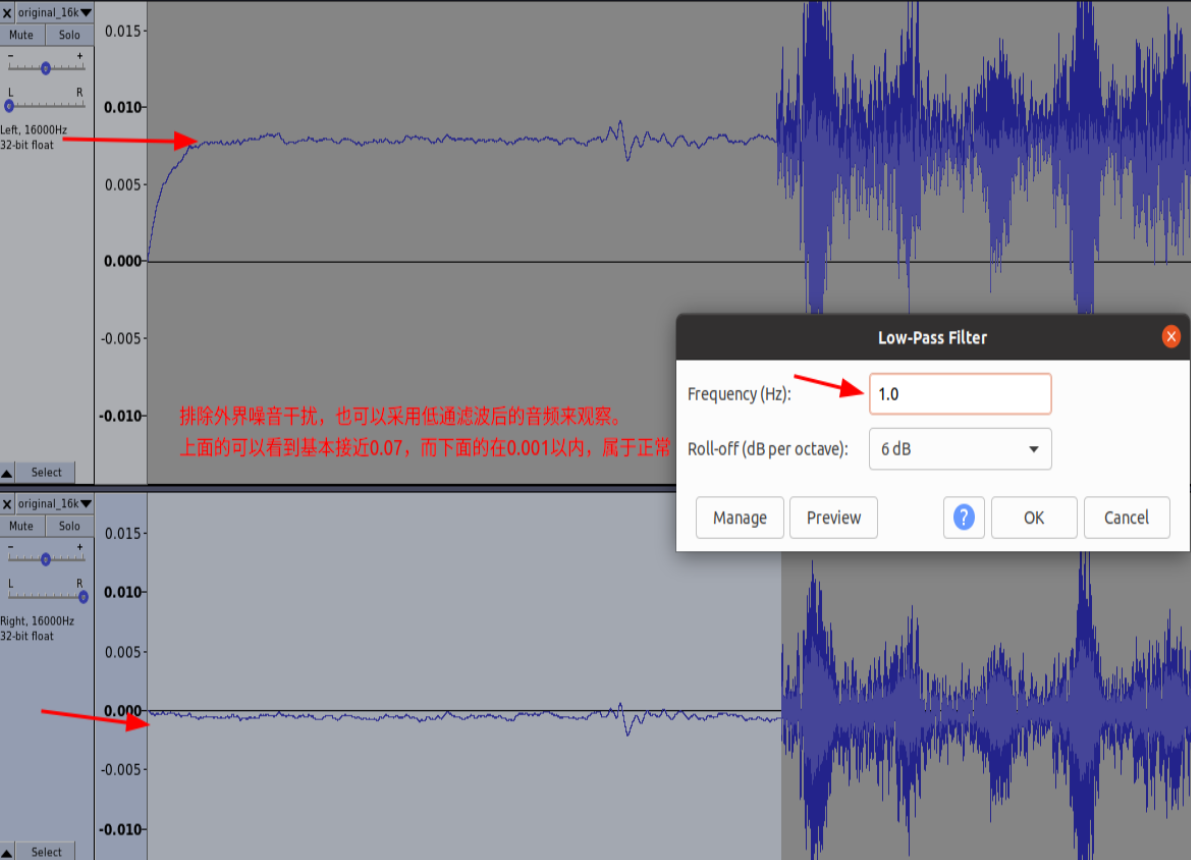
分析时为了排除噪声,使用低通滤波器,截止频率 1Hz。 麦克风通道: 模拟麦克风通路音频直流偏置 mic 处声压级 63dbc—— 直流能量不大于 mic 幅值的 1/3 举例模拟麦:0.005 *1/3,数字麦克风通路音频直流偏置 应该小于 0.0015 *1/3 回采通道: 0.5%(0.005)
-
问题音频
-
低通滤波后音频
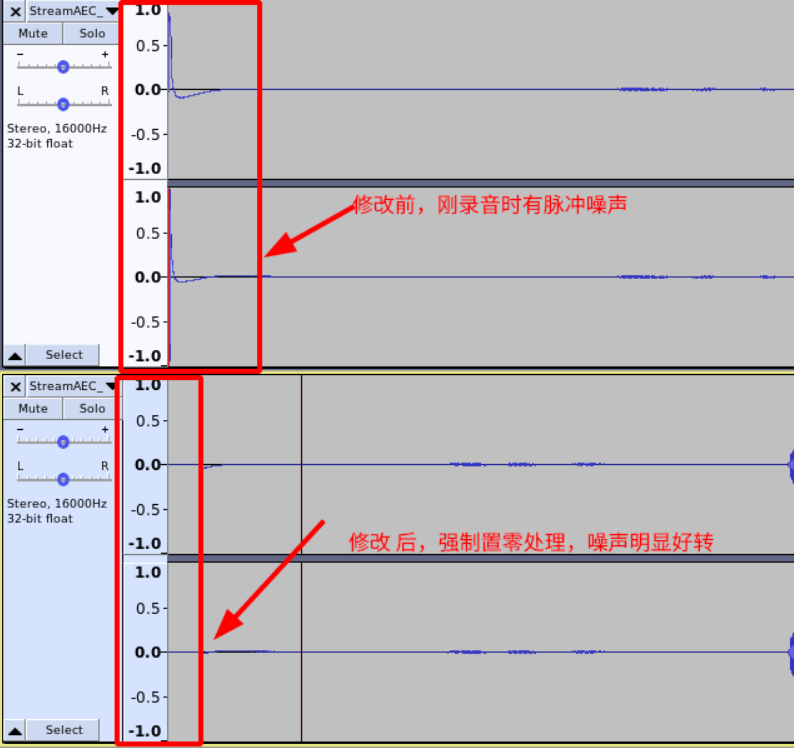
2.13录音爆破音
在一些设备录音,容易出现刚上电的时候有一个“哔哔”的脉冲噪声,如下图: 出现类似问题有可能是adc稳定时间较长,导致音频数据在稳定期间异常, 一般是硬件优化,如果无法优化,则可以考虑在hal层或驱动层将刚开始录音的音频置零处理。 在hal处理,将录音数据前4帧置零后效果:
3一些工具
3.1tinycap
在Android系统框架中,内核采用的是linux的kernel,所以驱动也沿用了alsa作为声卡驱动库, 作为移动设备的操作系统,Android对其做了一些精简,就是我们现在看到的的tinyalsa了。 所以我们可以通过tinyalsa的接口,直接访问音频驱动来播放或者读取音频数据。 可以作为检查驱动和硬件层是否正常的测试工具。
3.1.1如何编译生成tinyalsa工具
默认的Android系统之后编译tinyalsa的库,并不会把tinyalsa相关的测试工具编译出来,需要我们自己手动编译:
- 进入 source/external/tinyalsa 目录,mm 就可以将需要的tinyalsa工具编译出来。
- 编译完后,工具会在out/target/product/xxxxx/system/bin目录生成。
- 一般会生成tinycap,tinyplay,tinypcminfo,tinymix等工具。
- 如果是编译的时候将如下工具打包在img里,则在adb shell后任何目录都可以使用,如果没有的话,则需要手动将这些工具push到/system/bin/或/data目录下 如果是push到/data目录,则执行的时候需进入到/data目录,并使用加./执行。
1adb root
2adb remount
3adb push tinyalsa/* /system/bin
4adb shell
5chmod 777 /system/bin/tiny*
6tinycap xxx
7或者
8adb push tinyalsa/* /data
9adb shell
10chmod 777 /data/tiny*
11./data/tinycap xxx
3.1.2tinycap 录音参数说明
先说一下tinycap录音命令和参数:
“Usage: %s file.wav [-D card] [-d device] [-c channels] [-r rate] [-b bits] [-p period_size] [-n n_periods]\n”, argv[0]);
- -D 哪个声卡的意思, 比如usb声卡, 本机mic …
- -d 当前声卡下的哪个设备录音, 一般一个声卡下会有多个设备
- -c 录音通道数
- -b 采样精度,一般是16bit,但是如果需要标记位就要升高精度,如24bit或32bit
- -r 录音采样率
- -p period size:每个中断周期需要准备的音频空间大小
- -n 有多少组 period size
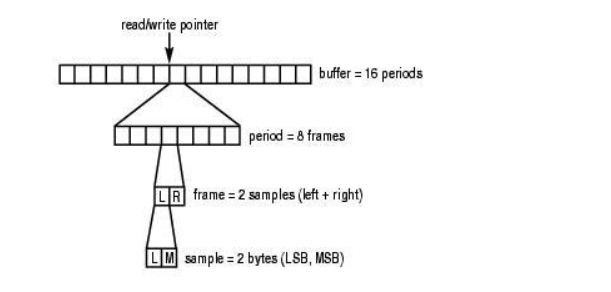
有很多同学对-p不是很理解, 这里详细说一下:
period : ALSA的官方是这样介绍的 :
A period is the number of frames in between each hardware interrupt.
意思就是硬件的每次中断所对应的frames数为一个period,简称一个周期吧.
A period is the number of frames in between each hardware interrupt.
意思就是硬件的每次中断所对应的frames数为一个period,简称一个周期吧。
exmple : 我们让codec工作在 stereo立体声,16-bits, 44.1KHZ 的采样流中,
[1] ‘stereo’ = 2;
[2] 1 analog sample 是16-bits = 2bytes;
[3]1 frame = (num_channels) * (1 sample in bytes) = (2 channels) * (2 bytes (16 bits) per sample) = 4 bytes (32 bits)
[4] Bps_rate = (num_channels) * (1 sample in bytes) * (analog_rate) = 2 * 2 * 44100 = 176400 Bytes/sec.
如果 ALSA每秒中断一次,那么我们就需要准备176400 bytes的空间.
如果ALSA半秒中断一次,那么我们就需要准备 176400/2 = 88200 bytes个大小的空间. 100ms中断一次的话我们就需要 176400 * 0.1 = 17640 bytes大小空间.
由上面的分析可以看出,我们可以控制PCM中断每次的产生,通过设置period 的大小,
[1] : 如果我们设置16-bit stereo @ 44.1Khz和period_size to 4410 frames =>(对于16-bit stereo @ 44.1Khz, 1 frame 等于 4 bytes 来说- 4410 frames equal 4410 * 4 = 17640 bytes) => 每100ms一次的中断将产生17640 个字节.
[2] : 相应的buffer_size 应至少为 2 * period_size = 2 * 4410 = 8820frames = 8820 * 4 = 35280bytes.
采集过程中ALSA会将按照我们自己设定的格式将数据按照每period大小存放在循环缓冲区中.
3.1.3tinycap 录音操作
针对tinycap如何录音,我们常常还会碰到一个问题就是刚刚拿到一台设备的时候,不知道要用什么参数,是选择哪个声卡进行录音。
这里提供一个简单的脚本方便大家查询录音参数
1#found_opendev.sh
2dir=/proc/asound/card*
3
4for file in $dir/*; do
5 if [[ $file == *c ]]; then
6 card="$file""/sub0/hw_params";
7 echo $card;
8 cat $card;
9 fi
10done
操作如下:
- 脚本先把这个脚本found_opendev.sh push到设备的/data目录下, 然后chmod 777.
- 启动一个app录音, 然后进到data目录./found_opendev.sh 会将当前hal下发录音参数打印出来(如下).
- 根据hal下发的参数,我们就知道tinycap该用哪些参数了.
- 如果你很悲剧的发现设备默认app无法正常录音,那需要用tinypcminfo来看声卡支持的参数了,然后根据经验,来试出哪一组参数是正确的。 如果发现tinypcminfo有时候无法打印声卡信息,则需要检查当前是否有root权限。
- 部分设备(mtk等)在录音先还需要切换一些指定mix, 需要在录音前先用tinymix -D x 来将该声卡的mix项打印出来,然后app录音的时候再tinymix -D x, 将录音时的mix打印出来, 对比一下录音前后有哪些mix不一样, 在没有设置mix无法录音的情况可以尝试tinycap录音前先将mix切换,再尝试录音.
1xxx:/ $ tinypcminfo -D 3
2Info for card 3, device 0:
3
4PCM out:
5cannot open device '/dev/snd/pcmC3D0p'
6Device does not exist.
7
8PCM in:
9cannot open device '/dev/snd/pcmC3D0c'
10Device does not exist.
11xxx:/ $ tinypcminfo -D 3
12xxx:/ $ exit
13
14$ adb root
15$ adb shell
16
17xxx:/ # tinypcminfo -D 3
18Info for card 3, device 0:
19
20PCM out:
21cannot open device '/dev/snd/pcmC3D0p'
22Device does not exist.
23
24PCM in:
25 Access: 0x000009
26 Format[0]: 0x000004
27 Format[1]: 00000000
28 Format Name: S16_LE
29 Subformat: 0x000001
30 Rate: min=16000Hz max=16000Hz
31 Channels: min=8 max=8
32 Sample bits: min=16 max=16
33 Period size: min=16 max=32768
34Period count: min=2 max=1024
3.1.4OverRun and UnderRun
当一个声卡活动时,数据总是连续地在硬件缓存区和应用程序缓存区间传输。
但是也有例外。
在录音例子中,如果应用程序读取数据不够快,循环缓存区将会被新的数据覆盖。这种数据的丢失被称为"over run".
在播放例子中,如果应用程序写入数据到缓存区中的速度不够快,缓存区将会"饿死"。这样的错误被称为"under run"。
在ALSA文档中,有时将这两种情形统称为"XRUN"。适当地设计应用程序可以最小化XRUN并且可以从中恢复过来。
XRUN状态又分有两种,在播放时,用户空间没及时写数据导致缓冲区空了,硬件没有 可用数据播放导致"under run";
录制时,用户空间没有及时读取数据导致缓冲区满后溢出, 硬件录制的数据没有空闲缓冲可写导致"over run"。
当用户空间由于系统繁忙等原因,导致hw_ptr>appl_ptr时,缓冲区已空
内核这里有两种方案:
- 停止DMA传输,进入XRUN状态。这是内核默认的处理方法。 继续播放缓冲区的重复的音频数据或静音数据。
- 用户空间配置stop_threshold
可选择方案1或方案2,配置silence_threshold选择继续播放的原有的音频数据还是静意数据了。
个人经验,偶尔的系统繁忙导致的这种状态, 重复播放原有的音频数据会显得更平滑,效果更好。
3.1.5alsa 参数说明
| 名词 | 解释 |
|---|---|
period_size |
每次传输的数据长度。值越小,时延越小,cpu占用就越高 |
period_count |
缓之冲区period的个数。缓冲区越大,发生XRUN的机会就越少。 format: 定义数据格式,如采样位深,大小端 |
start_threshold |
缓冲区的数据超过该值时,硬件开始启动数据传输。如果太大, 从开始播放到声音出来时延太长,甚至可导致太短促的声音根本播不出来;如果太小, 又可能容易导致XRUN |
stop_threshold |
缓冲区空闲区大于该值时,硬件停止传输。默认情况下,这个数 为整个缓冲区的大小,即整个缓冲区空了,就停止传输。但偶尔的原因导致缓冲区空, 如CPU忙,增大该值,继续播放缓冲区的历史数据,而不关闭再启动硬件传输(一般此 时有明显的声音卡顿),可以达到更好的体验 |
silence_threshold |
这个值本来是配合stop_threshold使用,往缓冲区填充静音 数据,这样就不会重播历史数据了 |
avail_min |
缓冲区空闲区大于该值时,pcm_mmap_write()才往缓冲写数据。这个 值越大,往缓冲区写入数据的次数就越少,面临XRUN的机会就越大Android samsung tuna 设备在screen_off时增大该值以减小功耗,在screen_on时减小该 值以减小XRUN的机会 |
在不同的场景下,合理的参数就是在性能、时延、功耗等之间达到较好的平衡。为什么在pcm_write()/pcm_mmap_write(),而不在pcm_open()调用pcm_start()?
这是因为音频流与其它的数据不同,实时性要求很高。作为 TinyAlsa的实现者,不能假定在调用者open之后及时的write数据,所以只能在有 数据写入的时候start设备了。
Mixer: 通过ioctl()调用访问kcontrols。
4测试说明
4.1音频验收测试
音频验收有很多指标,其中有一些对外部环境有一定的要求,如MIC底噪测试,增益测试, 信噪比测试等(需要静音室)。 也有一些不依赖外部环境的,如丢数据测试,直流偏置测试,混叠测试,参考回路底噪测试等。可以提测前先自己搭建测试环境测试。
4.2功能测试
在测试语音功能时,我们建议尽量保证周围唤醒安静,网络条件良好,测试用例符合产品设计。 在功能测试通过后,再根据实际语音使用场景,设计一定的干扰因数,再测试性能指标。 否则混杂在一起测试,常常会导致问题无法快速定位和分析。
4.2.1常见测试功能点
- 能否正常唤醒。
- 识别结果是否正确。
- 语义解析结果是否正确。
- 语音播报回复是否正确。
- 语音指令是否正常执行。
4.3性能测试
4.3.1资源占用测试
资源占用我们最关注的两个点: 1,CPU占用; 2,内存占用;
cpu占用可以采用top命令来观察,命令说明:
1usage: top [-Hbq] [-k FIELD,] [-o FIELD,] [-s SORT] [-n NUMBER] [-m LINES] [-d SECONDS] [-p PID,] [-u USER,]
2Show process activity in real time.
3
4-d Delay SECONDS between each cycle (default 3) 刷新间隔时间
5-m Maximum number of tasks to show 最多显示多少个进程
6-n Exit after NUMBER iterations 刷新次数
7-H Show threads 显示各个进程对应线程占用
8-p Show these PIDs 指定需要跟踪的进程PID
4.4厂测工具
4.4.1mic一致性测试
1.操作步骤和说明见源码中的注释。
4.4.2源码
1//Audacity_MIC_CO_TEST_v1.1.1.c
2#include <stdlib.h>
3#include <stdio.h>
4#include <math.h>
5
6/* Calc RMS (Root mean square) */
7void mic_amp_var_calc(unsigned short *p_buf, unsigned int len, float *p_outAmplitude)
8{
9 float tmp_amplitude1, tmp_amplitude2;
10 unsigned short audio_value;
11
12 for(unsigned int i=0; i<len; i++)
13 {
14 /* 归一化在0-1之间 */
15 audio_value = (p_buf[i]>0x8000) ? (0xFFFF-p_buf[i]+1) : p_buf[i];
16 tmp_amplitude1 = (double)audio_value/0x8000;
17
18 tmp_amplitude1 = tmp_amplitude1*tmp_amplitude1;
19 tmp_amplitude2 += tmp_amplitude1;
20 }
21 tmp_amplitude2 = tmp_amplitude2/len;
22 *p_outAmplitude = sqrt(tmp_amplitude2);
23}
24
25/* gcc Audacity_MIC_CO_TEST.c -o audio_cal -lm */
26int main(int argc, char *argv[])
27{
28 char *pAudioPath;
29 int chans;
30 int mic_num;
31 int offset = 0;
32 int samples = 0;
33
34 FILE *pFile;
35 unsigned int file_size;
36 unsigned short *audio_buf;//orignal audio data
37 unsigned short *chan_data;
38
39 if(argc < 4)
40 {
41 printf("Usage: %s file chans mic_num [0|1]\n", argv[0]);
42 printf("file -- audio pcm file\n");
43 printf("[0|1] -- 0=pcm file (default); 1=wav file.\n");
44 return -1;
45 }
46
47 pAudioPath = argv[1];
48 chans = atoi(argv[2]);
49 mic_num = atoi(argv[3]);
50 if (argc > 4) {
51 int v = atoi(argv[4]);
52 if (v == 1) {
53 offset = 44;
54 }
55 }
56 printf("pAudioPath=%s, chans=%d, mic_num=%d, offset=%d\n", pAudioPath, chans, mic_num, offset);
57
58 pFile = fopen(pAudioPath, "r");
59 if(pFile==NULL)
60 {
61 printf("not find audio file(%s)\n", pAudioPath);
62 return -2;
63 }
64
65 fseek(pFile, 0, SEEK_END);
66 file_size = ftell(pFile);
67 if (file_size <= offset) {
68 printf("audio file size (%d) too small\n", file_size);
69 fclose(pFile);
70 return -2;
71 }
72 fseek(pFile, offset, SEEK_SET);
73
74 audio_buf = (unsigned short *)malloc(file_size);
75 fread(audio_buf, file_size, 1, pFile);
76 samples = file_size/sizeof(unsigned short)/chans;
77 printf("samples=%d\n", samples);
78 chan_data = (unsigned short *)malloc(samples*sizeof(unsigned short));
79
80 float amp_ch = 0;
81 float db_ch = 0, min_db=0, max_db=-100.0, diff_db;
82 for (int ch=0; ch<mic_num; ch++) {
83 // get the mic channel data
84 for (int i=0; i<samples; i++) {
85 chan_data[i] = audio_buf[chans*i + ch];
86 }
87 /* step 1: 计算每个通道所有采样点的有效值(0-1之间) */
88 mic_amp_var_calc(chan_data, samples, &_ch);
89
90 /* step 2:有效值转变成db (dB定义为两个数值的对数比率,这两个数值分别是测量值和参考值) */
91 db_ch = (float)20*log10(amp_ch);
92 printf("mic_%d=%fdB (amp=%f); ", ch, db_ch, amp_ch);
93
94 /* step 3: 记录最大&最小dB */
95 if (min_db > db_ch) {
96 min_db = db_ch;
97 }
98
99 if (max_db < db_ch) {
100 max_db = db_ch;
101 }
102 }
103 printf("\n");
104 /* step 4: 计算各通道有效值的最大偏差(即一致性偏差),推荐4dB以内 */
105 diff_db = max_db - min_db;
106
107 printf("db min=%fdB, max=%fdB, diff=%fdB\n", min_db, max_db, diff_db);
108
109 fclose(pFile);
110 free(audio_buf);
111
112 printf("cal done \n");
113
114 return 0;
115}
4.5麦克风阵列音频检查方法及标准
下面列出了测试项和指标,具体的操作和要求,看这里
| 设备类型 | 序号 | 测试项目 | 测试音源 | 播放方式 |
|---|---|---|---|---|
| 裸板测试 | 1 | 通道相位一致性 | 1kHz 电信号 | N/A |
| 2 | 长时录音数据完整性 | 40min_test.mp3 | 安静环境外播录音&自播自录 | |
| 3 | 麦克风顺序 | N/A | N/A | |
| 4 | 通道幅值一致性 | 76dBC_sweep.wav | 安静环境外播录音 | |
| 整机测试 | 5 | 音频幅度要求 | mic_amplitude.wav | MIC 处63dBC 外播—MIC |
| ref_amplitude.wav | 最大音量自播—回路 | |||
| 6 | 总谐波失真 | 76dBC_sweep.wav | 自播自录DUT麦克风处本机场景验收音量(dBa) | |
| 7 | 麦克风通道信噪比 | EQ 白噪声 | 消声室MIC 处63dBC 和安静录音 | |
| 8 | 直流偏置 | N/A | 安静环境录音 | |
| 9 | 回采通道电噪声检测 | N/A | 安静环境录音 | |
| 10 | 恒频干扰 | N/A | 安静环境录音 | |
| 11 | 抗混叠 | 1~15kHz.wav | 安静环境自播自录 | |
| 12 | 通道相对延时 | 76dBC_sweep.wav | 自播自录SPK 出声口50cm 76dBC | |
| 13 | 结构共振/震动/异音 | 76dBC_sweep.wav | 自播自录SPK 出声口50cm 76dBC | |
| 14 | 麦克风通道气密性 | 76dBC_sweep.wav | 安静环境外播录音 |