
操作系统学习笔记 4非连续内存分配
200 Words|Read in about 1 Min|本文总阅读量次
熟悉完操作系统的第三篇章,开始学习第四篇章,关于操作系统的非连续内存分配。
0猜你喜欢
操作系统系列文章
4非连续内存分配
这部分是物理内存管理的第二部分。本章主要介绍管理非连续内存。
Q1:为什么需要非连续内存分配?
Q2:当前非连续内存的管理方法(分段和分页)
Q3:分页的数据结构(页表)
带着上述三个问题,开始本章的内容。
4.0为什么需要非连续内存分配
上一章内存管理中讲述了,连续分配内存管理方式,无论是首次适配,最佳适配,最差适配都会带来潜在的一系列问题。
连续内存分配的缺点
- 分配给一个程序的物理内存是连续的
- 内存利用率较低
- 有外碎片、内碎片的问题
非连续分配的优点
- 一个程序的物理地址是非连续的
- 更好的内存利用和管理
- 允许共享代码和数据(共享库)
- 支持动态加载和动态链接
非连续分配的缺点
如何建立虚拟地址和物理地址之间的转换
软件方案和硬件方案,但是纯软件方案的转换非常有限,还需要通过硬件方案来支持。目前两种硬件方案,分段和分页。
4.1 分段
分段主要考虑两点
- 程序的分段地址空间
- 分段寻址方案
4.1.1程序的分段地址空间
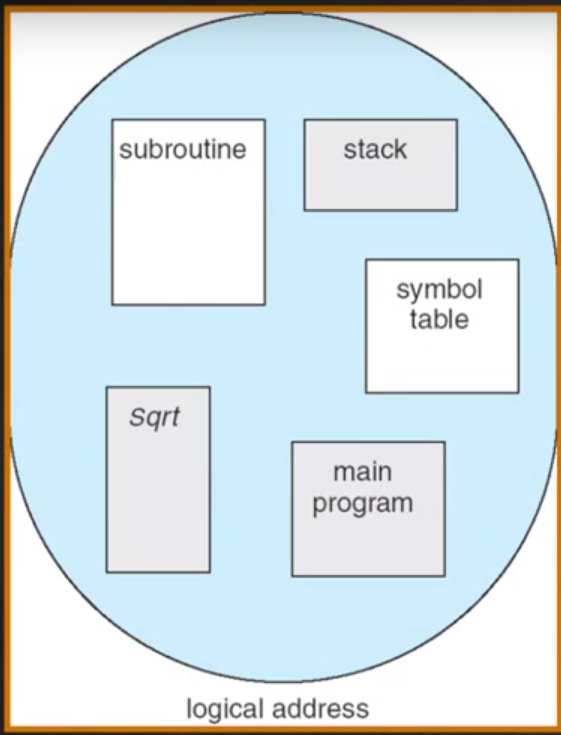 图4-1-1 分段的机制下应用程序的地址图
图4-1-1 分段的机制下应用程序的地址图
由上图4-1-1可以看到,分段其实是为了更好地分离和共享。
从应用程序的运行来说,它的虚拟的逻辑地址空间是一个连续的地址空间,虽然说是连续地址空间,但是分段之后有效的隔离开来。堆栈端可以分别放到不同的物理地址上面,用特定的权限管理起来。把堆区,运行栈,程序数据,库和用户代码都隔离开来。这样一来,可以让用户代码段和主程序段可以共享,能够相互之间进行访问。有些数据可以和另外的数据相对隔离,有些数据是可写的,有些数据是可读的。因为存在不同的区域,可以更加有效的进行管理分配,保证有效的保护机制实现。
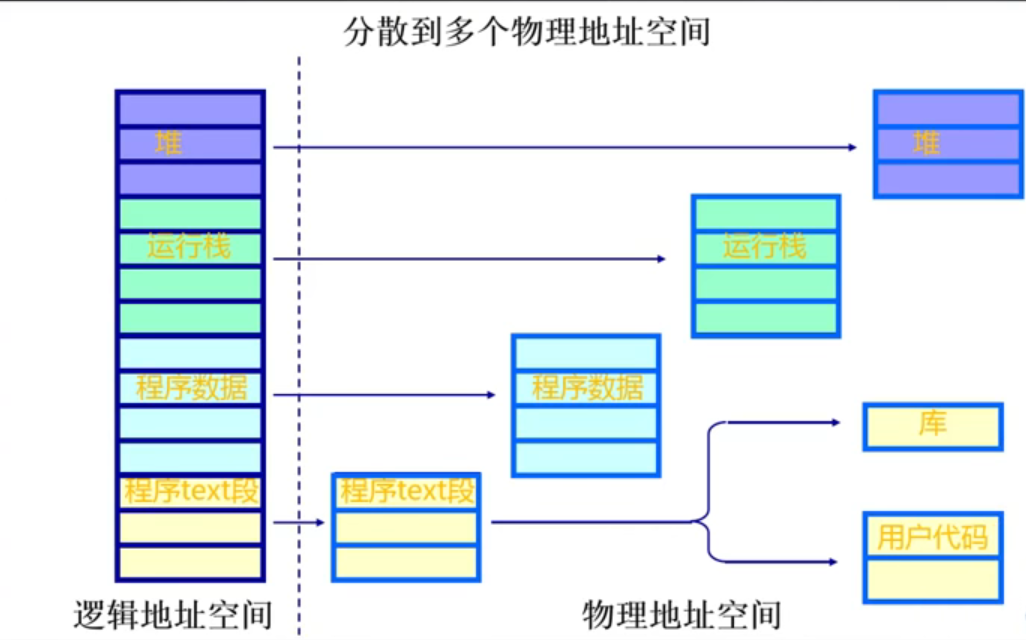
左边的连续逻辑地址空间,右边是不连续的物理地址空间,这就需要一种映射机制来相应建立关联。
4.1.2分段寻址方案
一个应用程序运行之后的地址,可以认为是一维的逻辑地址。
一维的逻辑地址和分段的物理地址对应,需要一种表述方法。
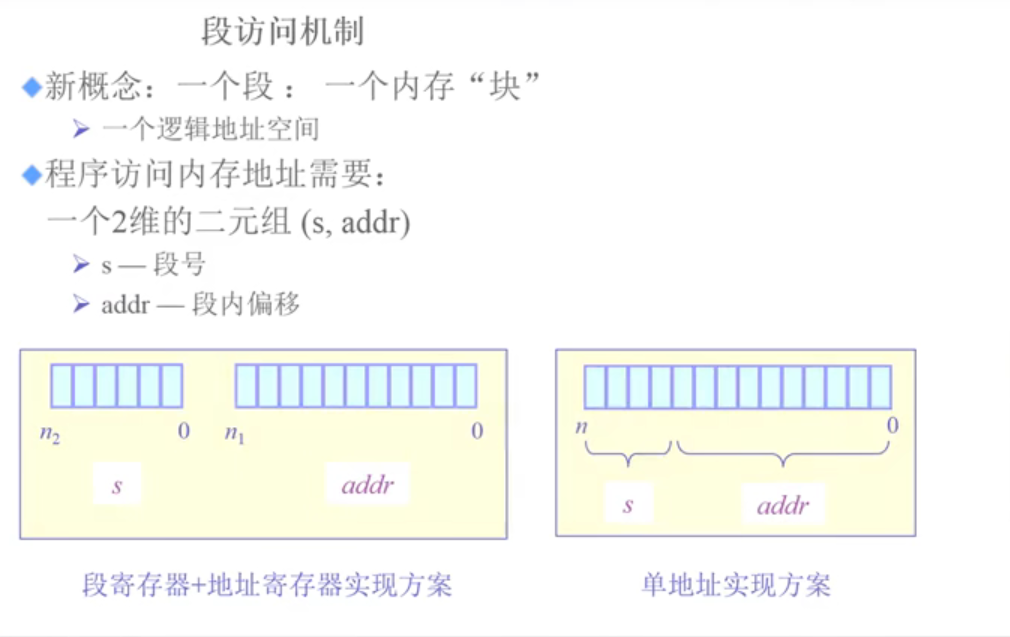 图4-1-2 段访问机制图
图4-1-2 段访问机制图
一维的逻辑地址是由很多段组成的,段可以不连续。一维的地址会被分成两块,一块是段的寻址,另外一块是段内偏移的寻址。根据上图4-1-2所示,这里可以有两种方式,段寄存器和地址寄存器的方案(X86),还有一种是单地址实现方案。
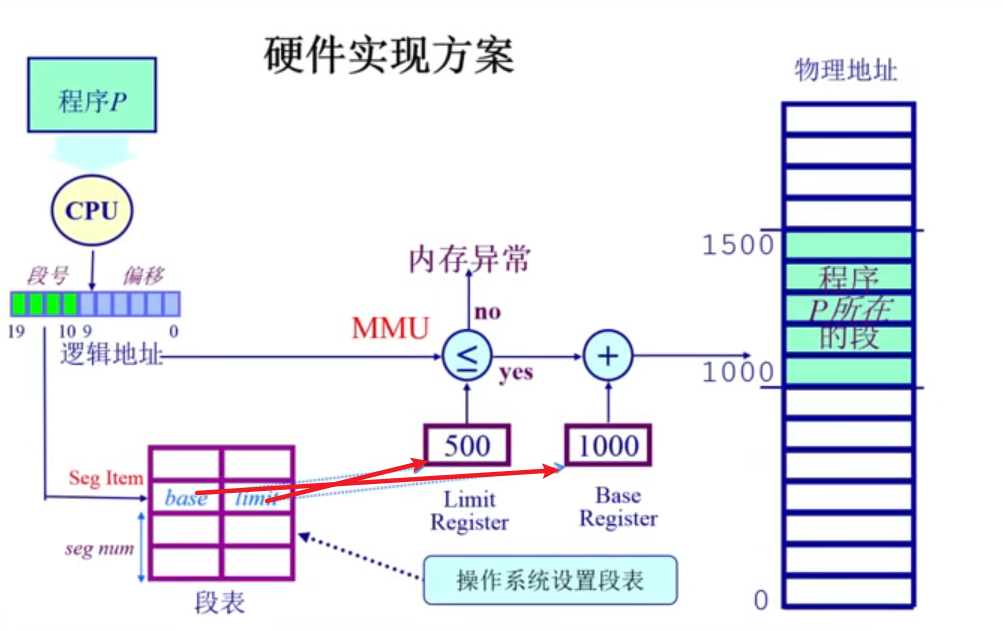
从左边看,左上角有一个可以运行的程序,CPU来执行每条指令。那么CPU就需要去寻址,地址可以采取单一的管理机制。那么把一个逻辑地址分成两块,上面部分是段号,下面部分是段内的偏移。通过段号,希望能够找到所在物理内存的起始地址,这个信息保存在段表中。另外,每个段的大小是不一样的,需要知道每个段的起始地址和长度,这个信息也是存放到段表里面的。段表里面有两个很重要的信息,一个是段的起始地址,另外一个是段的长度的限制。
段表的建立
段表由操作系统建立。在正式的寻址之前就应该建立好。操作系统建立好段表之后,这时候段机制就可以正常工作了。至于怎么建立段表和硬件有紧密的联系。
4.2分页
段机制相对而言,在现有的硬件中使用比较少,绝大多数CPU使用的还是分页机制。
分页主要是下面两部分
- 分页地址空间
- 页寻址方式
分段机制,需要知道段号和段内的偏移。分页也是类似,需要知道页号和页的偏移。主要的区别就是分段里面的段的尺寸是可变的,分页里面页的大小是固定的。
4.2.1分页地址空间
-
划分物理内存至固定大小的帧(frame指的是物理页)
大小是2的幂,例如,512,4096,8192等
-
划分逻辑地址空间至相同大小的页(page指的是逻辑页)
大小是2的幂,例如,512,4096,8192等
我们需要建立物理页和逻辑也地址的关系。
建立的方案,是转换逻辑地址为物理地址(pages to frames)
- 页表
- MMU(内存管理单元)/TLB(快表)
4.2.1.1帧(frame)
页帧代表物理内存地址,有两部分组成。页帧号和页帧内的偏移。
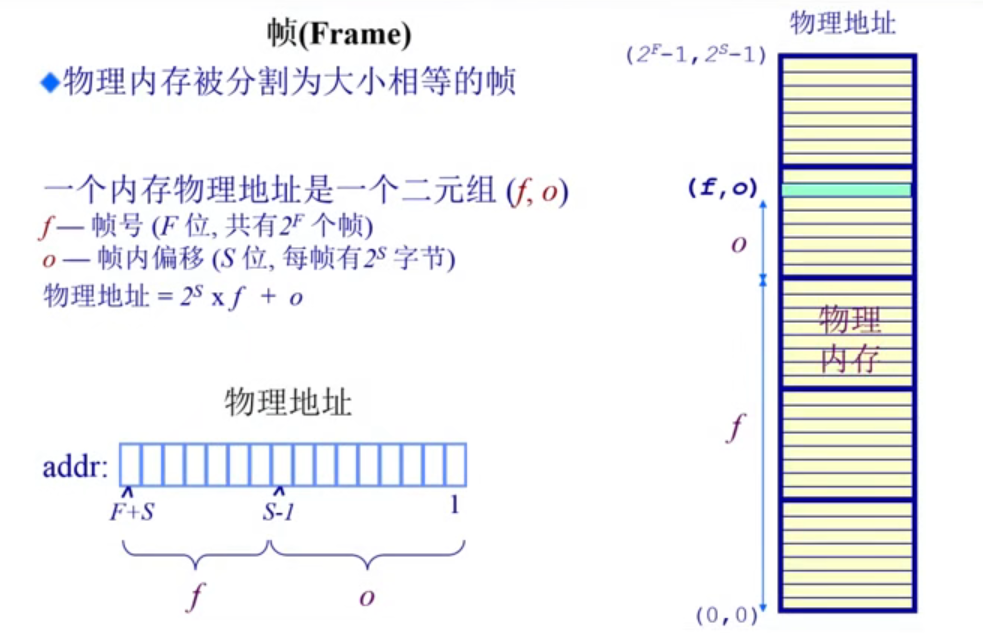
页帧号占了F位,页帧又占了S位。总共有2^F个帧和每帧有2^S字节。
帧号可以理解成一本书的第几页,帧内偏移可以理解为一本书的第几页的第几行。我们知道帧号和帧内偏移,就可以知道具体物理地址,物理地址为2^S*f+o
具体计算实例如下所示

结果含义:(从0计数)第三帧的第六偏移的位置计算,其中每一帧切成512个偏移量,每帧中的各个便宜前7bit的代表帧号且相同,后9bit代表帧里面具体的偏移量。
4.2.1.2页(page)
计算方式类似前面的帧。区别在于,页号的size和帧号的size可能不一样。但是每个页的大小,每个页帧的大小是一样的。我们可以得出,相应的页号和相应的页内偏移的逻辑地址,可以得到它对应的实际逻辑地址。
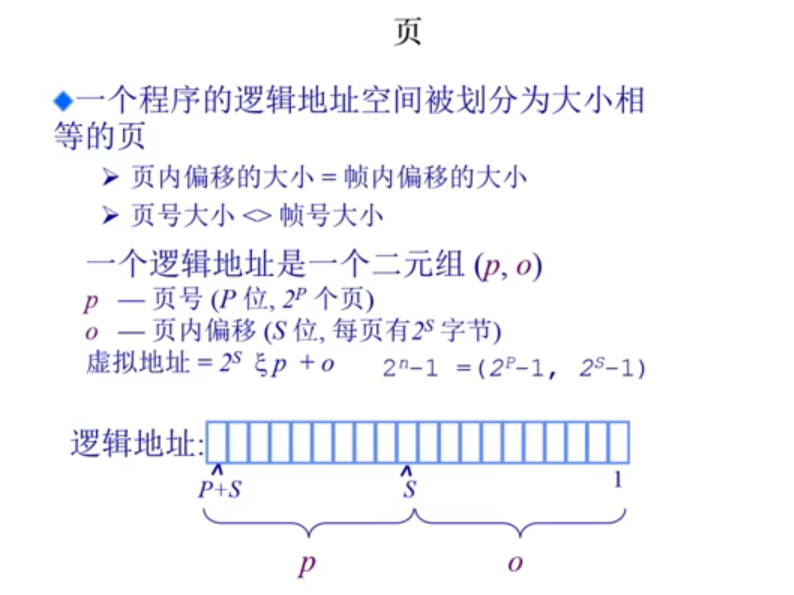
4.2.2页寻址方式
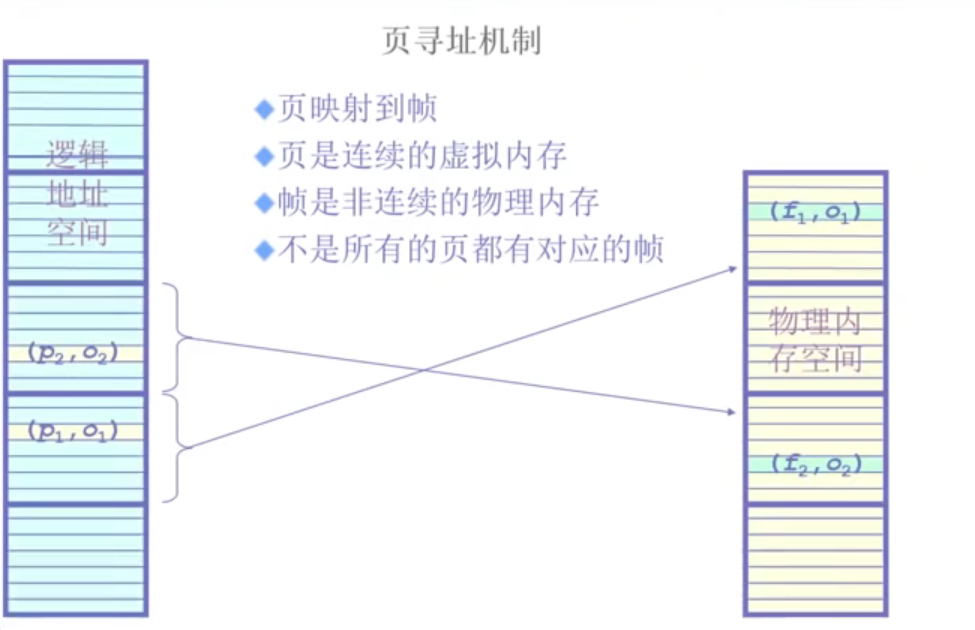
一个页的偏移大小虚拟和物理是一致的,但总的地址空间,虚拟和物理可能是不一致的。页号位数可能实不相等的,但偏移位数是相等的,这样页表就只存储页号就可以了,偏移地址不用存,页号位数不相等意味着逻辑内存中可能找不到对应的物理内存。
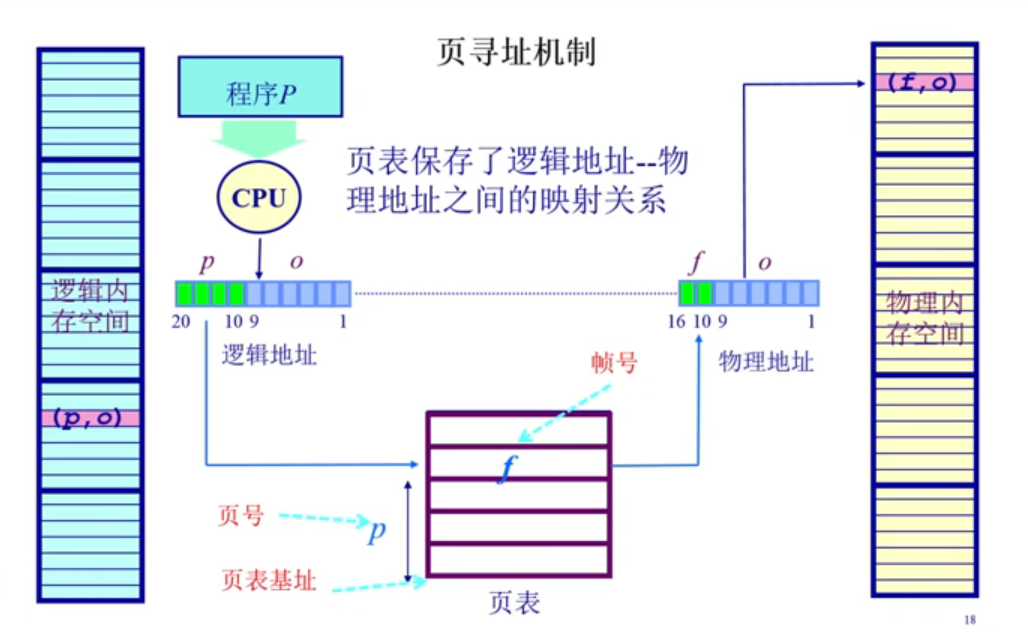 图4-2 页寻址方式图
图4-2 页寻址方式图
首先程序运行时候,CPU获取寻址,无论是执行一条语句还是访问一个数据,需要直到指令或者数据所在的地址。这个地址是一个逻辑虚拟地址,上图4-2所示,可以看到分成两块。一块是o,一块是p。p是页号,建立一个索引,page table,用于查询。页表中存的是以页号为索引的对应那一项的内容,放的内容是帧号。
有了索引的信息之后,就可以通过页号查到对应的帧号。
通过页帧号和偏移大小可以知道帧号和偏移大小。最终找到对应的物理地址。
页表page table是谁来建立的?
页表是操作系统来建立。建立好页表之后,才能让程序正常的完成映射关系。在操作系统初始化,内存管理使能分页机制的时候,就需要建立好。
一般来讲,逻辑地址空间和物理地址空间大小不一致,且逻辑地址空间大于物理地址空间。可以知道逻辑地址是一个连续的寻址,而映射到物理地址是一个不连续的寻址,分散在不同的物理地址空间。这样的好处,有助于减少内存碎片。
4.3 页表
通过上面的篇章分页机制,知道页表可以有效的实现这种分页机制。
但是页表是如何实现的,怎么样实现高效,怎么样实现节省空间,这个需要操作系统和硬件配合共同完成的一个目标。
页表
- 转换后备缓冲区(TLB)
- 二级/多级页表
- 反向页表
4.3.1页表-概述、TLB
4.3.1.1页表概述
页表其实就是一个大数组。索引就是页号,索引所对应的就是帧号。
CPU会查这个页表在什么地方,它的起始地址在哪,通过page number算出index,然后去寻址到对应的页表项,把对应的帧号取出来。帧号叠加页内偏移量,可以得到对应的物理地址。
下面4-3-1所示,在页表中除了帧号还有一些bit值。这些有特殊的用途,可以表示这个页表项是否是一个合法的页表项(对应的物理页在内存中是否存在)
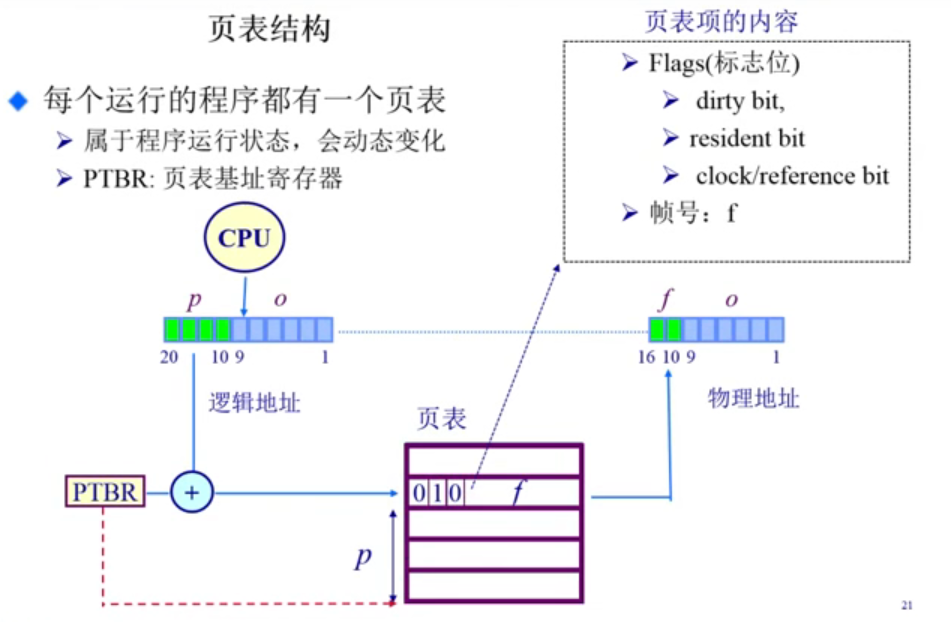 图4-3-1 页表结构图
图4-3-1 页表结构图
页表在地址转换中的例子
图4-3-2 地址转换实例图
逻辑地址空间:有16bit,具有64k的地址空间。
物理地址空间:有15bit,具有32k的地址空间
逻辑地址的(4,0)代表的含义:逻辑页号是4,页内偏移是0。查询对应的页表,中间的0代表对应的物理页是否存在,0为不存在,1是存在,上图所示4-3-2,也表中出现Flags项中第二位为0,说明找不到对应的物理地址,内存访问异常。
逻辑地址的(3,1023)代表的含义:逻辑页号是3,页内偏移是1023。查询对应的页表,出现Flags项中第二位为1,说明存在该物理地址,查到对应的帧号为0x100,对应4。映射出来的物理帧号为4,页内偏移量为1023,运算出来可以看到为(4,1023),正好对应图4-3-2的右侧的顶部位置。
4.3.1.2分页机制的性能问题
| 性能开销 | 具体问题 |
|---|---|
| 可能会带来时间上空间上比较多的花销 | 访问一个内存单元需要2次内存访问1)一次用于获取页表项2)一次用于访问数据 |
| 页表可能非常大 | 1)64位机器如果每页1024字节,那么一个页表的大小会是2^64/2^10=2^54,容量非常大。2)计算机中有多个应用程序,每个程序都有自己单独的一个页表。 |
4.3.1.3解决方式
-
缓存
缓存的话可以放到离CPU很近的地方,提升访问速度。
-
间接访问
间接访问,把很大的空间拆成多个小的空间,多级的页表方式可以有效地缓解页表空间占据过大的问题。
4.3.1.4TLB
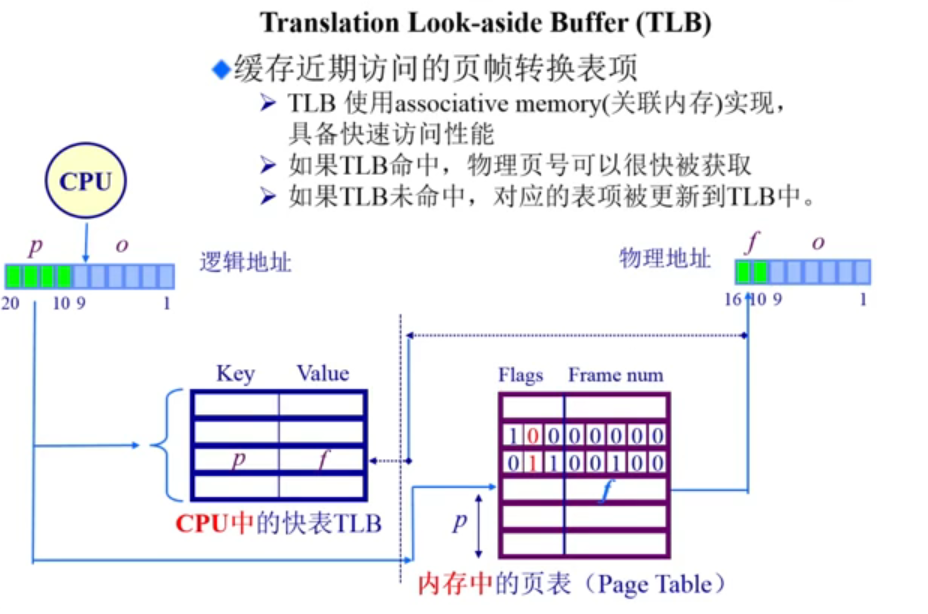
TLB可以解决时间的问题。CPU里面的mmu(内存管理单元),在内存管理单元里有一个TLB(缓冲),用于缓冲页表里面的内容。
TLB是一个特殊的区域,里面包含两项,key和value。TLB的表项是由相关的存储器实现的。相关存储器是一种快速的查询的存储器,可以并发的查找,但是实现的容量是有限的。经常用到的页表项可以放到TLB里面去,这样可以提升访问速度,就不需要再查页表。
当CPU得到一个逻辑地址的时候,首先会根据p到TLB进行查询,如果能够在TLB的中查询到,可以找到对应的帧号,然后在根据页内偏移得到对应的物理地址。如果在TLB中找不到,即未命中,这个时候会去查找页表,页表中的Flags中间位如果为1,同样可以找到对应帧号,然后根据帧号和页内偏移量得到对应的物理地址,并把对应的帧号取出来存在TLB中。
TLB相关问题
-
TLB缺失问题
32位系统,一个页一般是4096(4K)。如果每个地址都需要访问,才会引起TLB缺失,这个是可以接受的程度。引入某种机制,使得TLB的缺失尽量小。比如尽量写的程序有局部性,让程序有访问的局部性,可以把访问集中在一个区域里,可以有效的减少TLB的缺失。
-
过程的软硬件参与问题
关于TLB未命中之后,会从页表里面取出帧号,并将对应页号和帧号作为k/v键值对存到TLB中。根据CPU特征不同,x86的CPU上述过程会在页表中完成,不需要操作系统来参与;另一类CPU的话,是由操作系统完成,需要软件完成。
4.3.2 页表-二级、多级页表
通过TLB机制可以把常用的页表项缓存到CPU中,从而使得地址映射关系很快,不需要多次访问内存。但是空间上的问题就需要多级页表的方式。
首先先看二级页表,逻辑地址也做了进一步的区分。
页号和页内偏移量进行细化,把页号分成两部分,页内偏移量不变,页号分成p1的页号和p2的页号,对应一级页表和二级页表的页号。这样使得大地址寻址,变成对n个小的table寻址。
4.3.2.1二级列表
寻址过程
如下图4-3-3所示,大的页号分成两块,p1和p2。
- 寻址开始需要寻找一级页表,一级页表的起始地址CPU是知道的,p1的num作为index,一级页表的页表项存了一个值,这个值是二级页表的起始值。
- 二级页表的起始值知道之后,根据二级页表的p2,p2的num作为index,二级页表的index和一级页表存的二级页表的起始地址,形成二级页表中的针对p2的index的页表项,二级列表中存的则是最终的帧号。
- 加上页内偏移量,可以找到最终的物理地址。
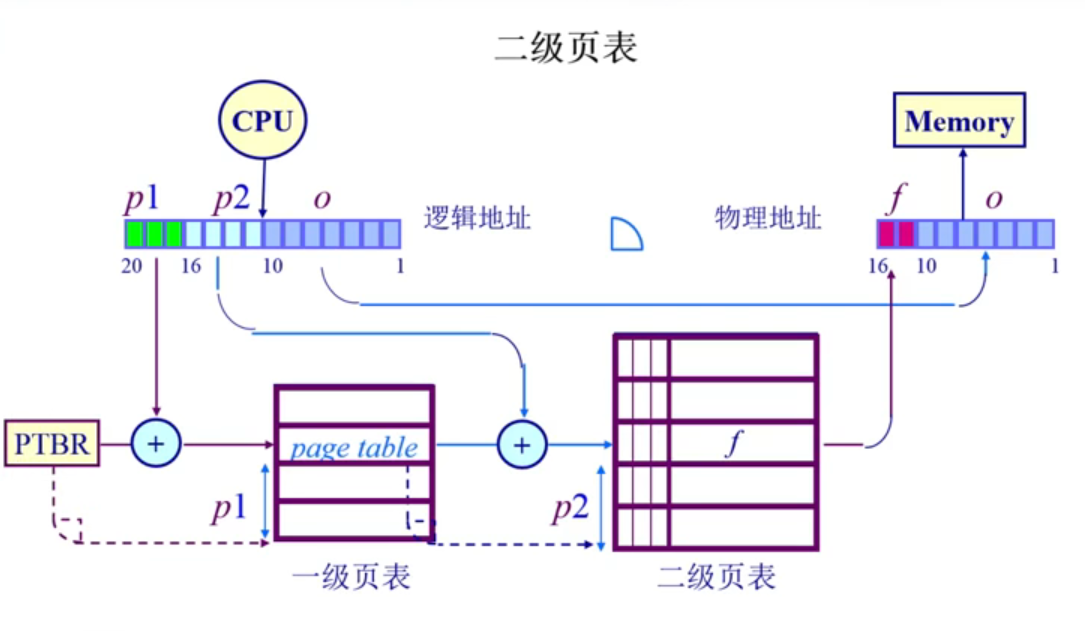 图4-3-3 二级列表图
图4-3-3 二级列表图
如果p1指向的页表项不存在,意味着驻留位Flags为0,代表映射关系不存在,二级列表不需要存档对应的帧号,因为帧号不存在。相比较一级列表,及时映射关系不存在,依然要保留对应的空间,这样会更加省空间。
4.3.2.2多级页表
运用二级列表的关系,通过构造索引树,访问的开销会越来越大,但好处是节省大量空间。
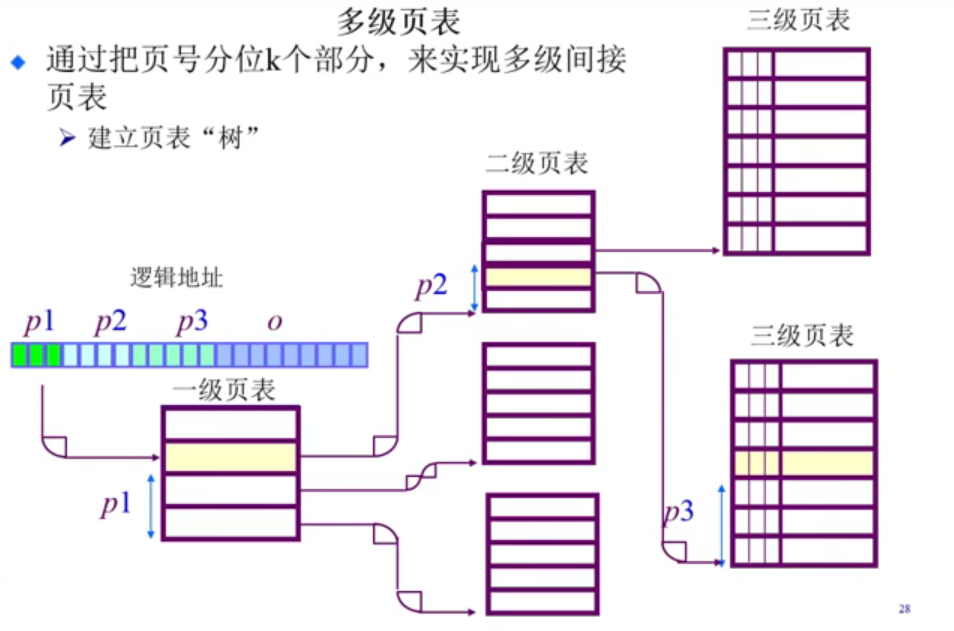
4.3.3 页表-反向页表
单级页表或者是多级页表,它的页表大小都和逻辑地址空间大小有对应关系。逻辑空间地址越大,对应的页表也会越多。存在一种机制,使得页表大小和逻辑地址空间大小没有直接的关系,尽量和物理地址空间建立一种联系,这种机制的思想就是反向页表的思想。

如果有大的64位的地址空间,需要建立五级页表。前向映射页表变成繁琐,之前的单级页表或者多级页表都是以逻辑页的页号作为索引号,来索引一个大数组。反向页表以物理页作为索引号,来索引一个数组,查找逻辑页的页号。
4.3.3.1页寄存器方案
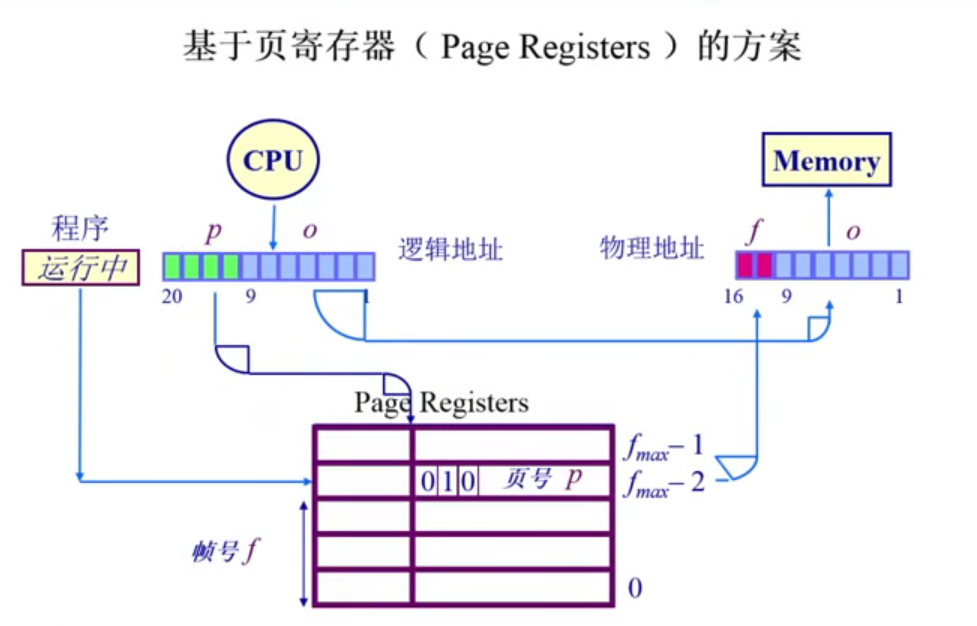
这种方法,相当于寄存器的容量只与物理地址空间大小相关。但是缺点是如何根据页号找到页帧号。

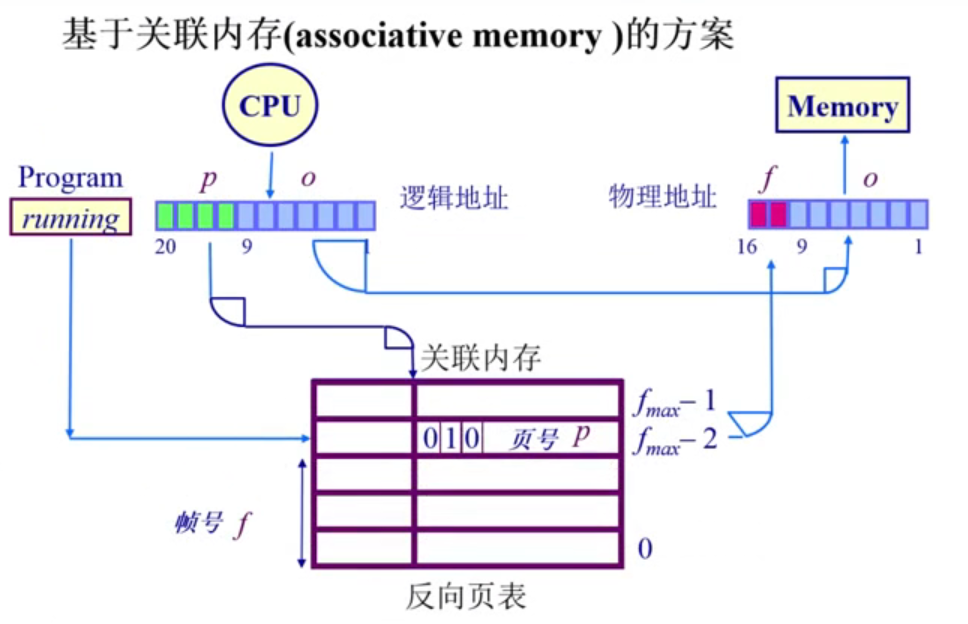
4.3.3.2关联内存方案
这是一种特殊的寄存器,可以并行查找页号所对应的页帧号
k是页号,v是对应的页帧号,类似TLB。
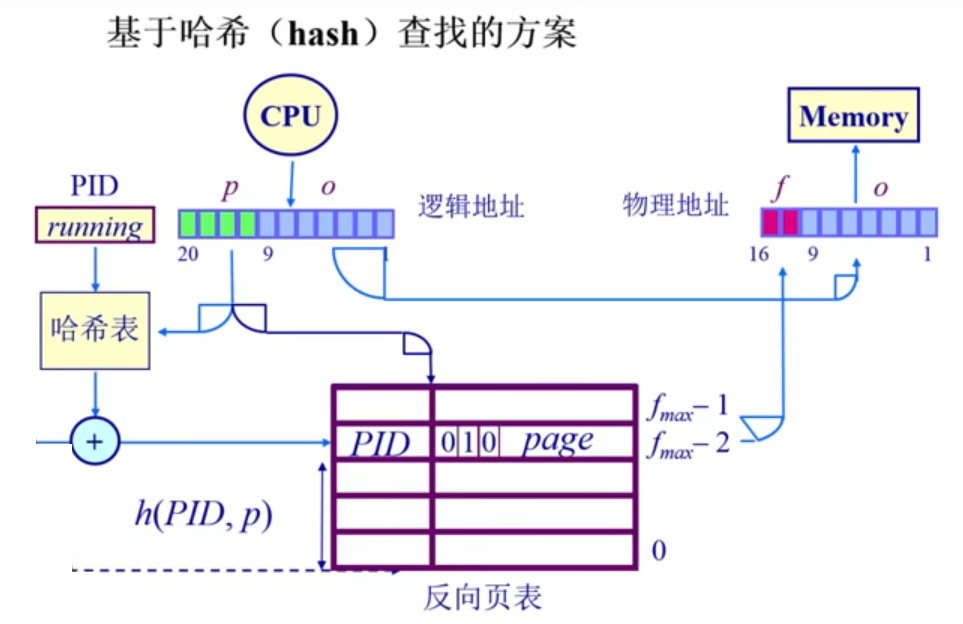
4.3.3.3哈希查找方案
把关联内存方法,用另一种机制实现。把page num查找frame num的过程用hash table来实现。hash表是一种数学计算方法,输入是page num,输出是frame num。哈希函数处理软件计算,为了提高效率,更多的会用到硬件加速。另外再加上当前运行的程序的id标识号,page num和pid可以很好的做一个input,来设计出简洁的hash函数,算出对应的帧号。但同时会引入哈希冲突,多个不同输入会存在相同的输出。
4.3.3.4总结
个人理解:建立的反向页表根据页帧数量(物理地址大小)来建立,转换时方法跟以往一样都是通过逻辑地址转换物理地址,只是如果是哈希查找方法,会引入哈希冲突问题。
反向页表,一般高端CPU才会引入这个机制,好处是不收逻辑地址空间和虚拟地址空间大小的限制,它容量可以做的很小,只和物理地址空间相关。以往每一个运行的程序都需要一个页表,但是反向页表整个系统只需要一个反向页表,是以物理页帧的页帧号作为index的建立的表,这个表和有多少进程是没有关系的,但是需要高速的硬件处理机制,哈希运算机制和解决哈希冲突的机制。
| 反向页表实现方案 | 好处 | 缺点 |
|---|---|---|
| 页寄存器 | 1)转换表的大小对于物理内存来说很小2)转换表的大小跟逻辑空间的大小无关 | 1)需要的信息对调了,即根据帧号可以找到页号2)如何转换回来?即根据页号找到帧号3)在需要在反向页表中搜索想要的页号 |
| 关联内存 | 1)如果帧数较少,页寄存器可以被放置在关联内存中2)在关联内存中查找逻辑页号,成功标识:帧号被提取;错误标识:页错误异常 | 1)大量的关联内存非常昂贵2)难以再单个时钟周期内完成3)耗电 |
| 哈希查找 | 1)在反向页表中通过哈希算法来搜索一个页对应的帧号2)页i被放置在表中f(i)位置,其中f是设定的哈希函数3)为了查找页i,执行下列操作i)计算哈希函数f(i)并且使用它作为页寄存器表的索引ii)获取对应的页寄存器iii)检查寄存器标签是否包含i,如果包含,则代表成功,否则失败 | 1)会引入哈希冲突,多个不同输入会存在相同的输出2)反向页表是放在内存中,哈希计算也需要从内存中读取和计算,内存的开销会很大,也需要引入类似TLB机制缓存起来 |