
ThreadLocal之初出茅庐
1800 Words|Read in about 9 Min|本文总阅读量次
我们使用ThreadLocal能够解决线程局部变量统一定义问题,多线程数据不能共享的问题,使得每一个线程单独维护自己线程内的变量值(set、get、remove)。
ThreadLocal含义
线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。ThreadLocal可以让每一个线程拥有自己的变量副本,不会和其他线程的变量副本冲突,实现了线程的数据隔离。
Thread.java里面有一个全局变量
1//ThreadLocal变量属于这个当前线程,并且通过ThreadLocalMap表里面维持了一个ThreadLocal类 2ThreadLocal.ThreadLocalMap threadLocals = null;
其实就是一句话,ThreadLocal内部类是ThreadLocalMap。当前线程ThreadLocal<?>对象,和< ? >类型的对象构成了Entry数组,存放在了ThreadLocalMap里面。
ThreadLocal类比故事
为了通俗理解,这里讲一个关于老师上课的故事。
一个班级有30个学生,每个学生都有一个口袋,口袋里可以存放东西,口袋有16个格子,可以装16样东西。数学老师小数上课,拿出尺子。但是只有一把尺子不够分,那么数学老师小数又拿了30个尺子副本,发给30名学生,这样每个学生都可以分到属于自己的尺子。学生们在尺子上面写上自己和老师的名字,这样其他同学就不会拿错尺子,最后将尺子放入自己口袋的一个容纳尺子的格子里。
这里的一名数学老师相当于是< ? >,学生相当于是线程,班级相当于是线程池,也就是说目前线程池里面有30个线程。学生的口袋相当于是ThreadLocalMap,尺子就是ThreadLocal,这个尺子是这个数学老师给这个学生单独分配的尺子,仅且只能这个学生使用。并且尺子在班级里数据是共享的,所有学生的尺子都是老师给的尺子的副本。其他学生只能拿自己的尺子,因为尺子上写了自己的名字。尺子上又写了老师的名字,说明学生拿到的这个尺子是数学老师给的。
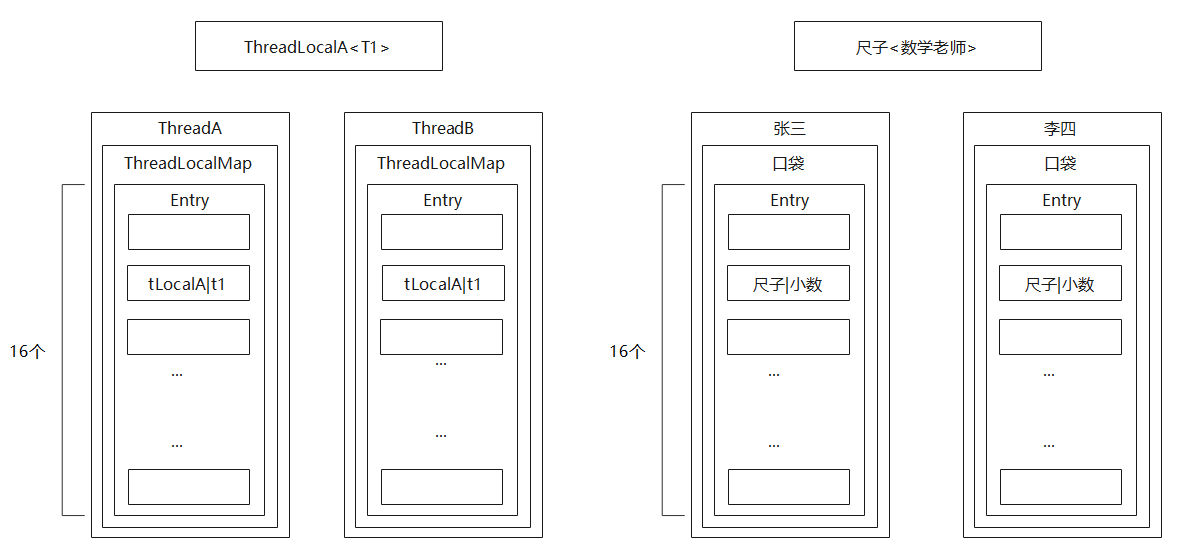 Thread、ThreadLocal和ThreadLocalMap
Thread、ThreadLocal和ThreadLocalMap
然后数学老师小数上完课,语文老师小语开始上课。语文老师小语拿出钢笔,钢笔也不够分,语文老师小语就又拿出了30只钢笔副本,发给30名学生,这样每个学生都可以拿到属于自己的钢笔。学生们在钢笔上面写上自己和老师的名字,这样其他同学就不会拿错钢笔,最后将钢笔放入自己口袋的一个容纳钢笔的格子里。
说明目前学生口袋里除了数学老师小数给的尺子,还有语文老师小雨给的钢笔,也就是每个学生都存在尺子和钢笔。这里的尺子和钢笔属于班级里的共享变量。
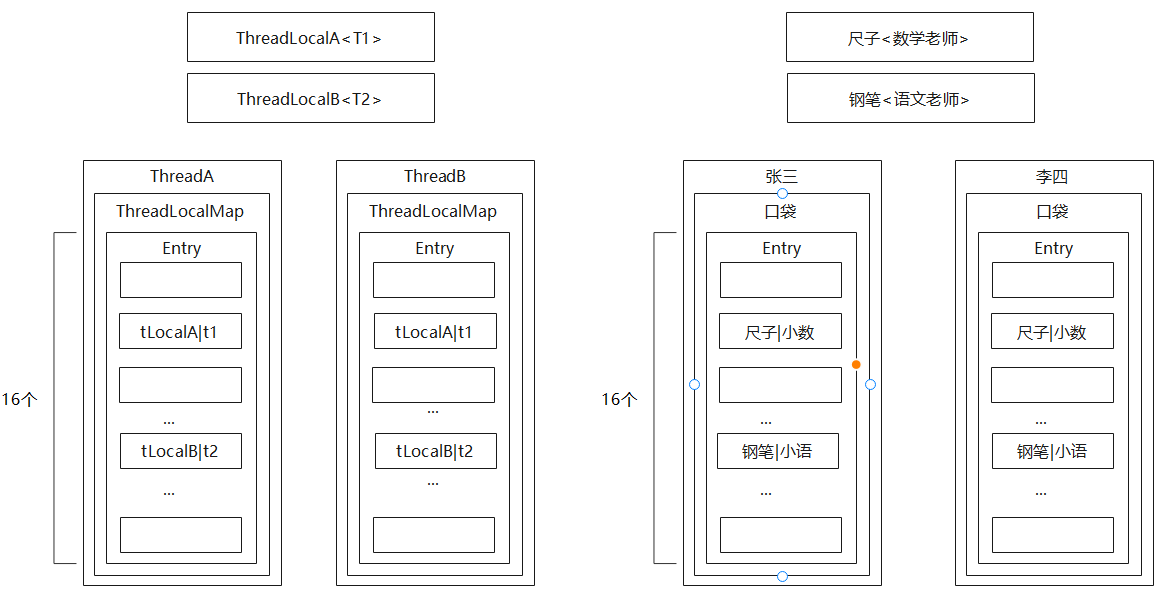 Thread、ThreadLocal和ThreadLocalMap
Thread、ThreadLocal和ThreadLocalMap
源码分析
讲完了故事,接下来主要对ThreadLocal源码进行解析
ThreadLocal最核心的就是set,get和remove
set
1//设置这个线程局部变量map保存当前线程的副本的值value
2public void set(T value) {
3 Thread t = Thread.currentThread();
4 ThreadLocalMap map = getMap(t);
5 if (map != null)
6 map.set(this, value);
7 else
8 createMap(t, value);
9}
10
11//这个返回的就是Thread中一个全局变量ThreadLocalMap类型的对象threadLocals
12ThreadLocalMap getMap(Thread t) {
13 return t.threadLocals;
14}
15
16//创建与 ThreadLocal 关联的映射ThreadLocalMap。
17void createMap(Thread t, T firstValue) {
18 t.threadLocals = new ThreadLocalMap(this, firstValue);
19}
这里面调用了ThreadLocal内部类ThreadLocalMap的方法,主要是为了创建map表,存放Threadlocal。
get
1//返回当前线程的 this 局部变量map保存的线程副本值
2//如果没有找到该线程副本,返回线程本地的当前线程值
3public T get() {
4 Thread t = Thread.currentThread();
5 ThreadLocalMap map = getMap(t);
6 if (map != null) {
7 ThreadLocalMap.Entry e = map.getEntry(this);
8 if (e != null) {
9 @SuppressWarnings("unchecked")
10 T result = (T)e.value;
11 return result;
12 }
13 }
14 return setInitialValue();
15}
16
17//初始化,这个方法会覆写原来的set
18private T setInitialValue() {
19 T value = initialValue();
20 Thread t = Thread.currentThread();
21 ThreadLocalMap map = getMap(t);
22 if (map != null)
23 map.set(this, value);
24 else
25 createMap(t, value);
26 return value;
27}
28
29//每个线程只有一次,跟remove配套使用,可供子类覆写
30protected T initialValue() {
31 return null;
32}
这里面主要是查询当前thread里面创建的map表,查询map中threadlocal类型的this对应的value是否存在,存在返回值。否则两种情况,不存在map表则先创建表,其次不存在this对应的value值,那么就生成一个null(子类可覆写)的value,保存在map表中。
remove
1//移除当前线程的ThreadLocal对象
2public void remove() {
3 ThreadLocalMap m = getMap(Thread.currentThread());
4 if (m != null)
5 m.remove(this);
6}
这里面主要是一出当前线程的ThreadLocalMap类型的表。
ThreadLocalMap
上述好多真正的操作放在ThreadLocalMap中了,当相当于对ThreadLocal做了隔离,不用直接接触真实操作,都在ThreadLocalMap完成即可。也就是表面上操作了ThreadLocal set,get和remove,实际上都是在ThreadLocalMap中的操作set,get和remove。
构造函数
ThreadLocalMap,有两个构造,目前先看有两个参数的
1ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
2 table = new Entry[INITIAL_CAPACITY];
3 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
4 table[i] = new Entry(firstKey, firstValue);
5 size = 1;
6 setThreshold(INITIAL_CAPACITY);
7}
8
9private void setThreshold(int len) {
10 threshold = len * 2 / 3;
11}
这个ThreadlocalMap构造做了三件事。
1)ThreadLocalMap内部类全局变量table默认新建了一个大小为16的数组
2)新构造了一个Entry的键值对,K-V,并且使用了散列算法存放到table表里
3)设置初始化扩容阈值,第一次设置为10
存储结构Entry
这个ThreadLocalMap内部的类,数据结构为数组
1//Entry构造两个值,一个为key,ThreadLocal<?>,一个是value
2//其中key是一个弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
3//其中value是强引用,不会被垃圾回收
4static class Entry extends WeakReference<ThreadLocal<?>> {
5 /** The value associated with this ThreadLocal. */
6 Object value;
7
8 Entry(ThreadLocal<?> k, Object v) {
9 super(k);
10 value = v;
11 }
12}
ThreadLocalMap中的Entry的key使用的是ThreadLocal对象的弱引用,在没有其他地方对ThreadLocal依赖,ThreadLocalMap中的ThreadLocal对象就会被回收掉。
1//初始容量,必须为2的幂
2private static final int INITIAL_CAPACITY = 16;
3//Entry表,大小必须为2的幂
4private Entry[] table;
5//表里entry的个数
6private int size = 0;
7//重新分配表大小的阈值,默认为0
8private int threshold;
9
10//环形意义的下一个索引
11private static int nextIndex(int i, int len) {
12 return ((i + 1 < len) ? i + 1 : 0);
13}
14
15//环形意义的上一个索引
16private static int prevIndex(int i, int len) {
17 return ((i - 1 >= 0) ? i - 1 : len - 1);
18}
其数据结构,优点类似循环数组,也可以理解为环形逻辑,下图所示
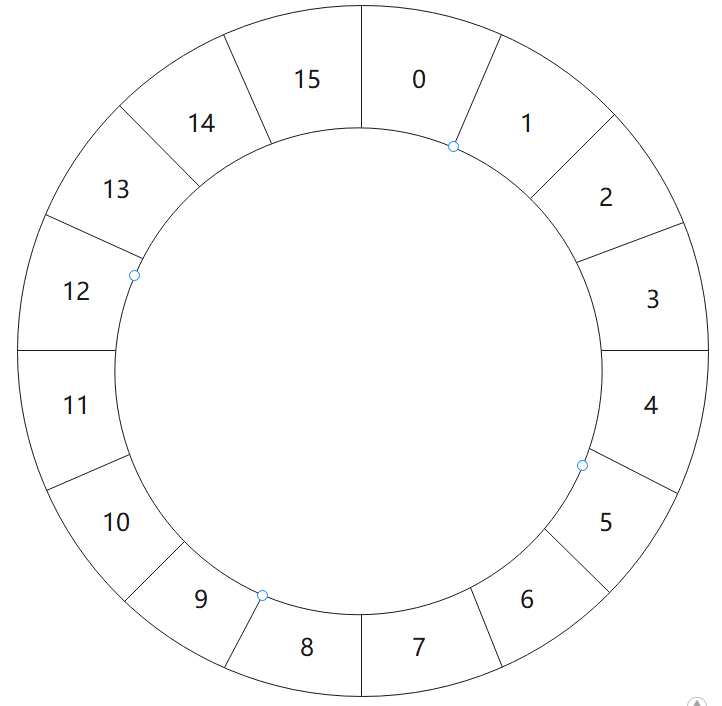 ThreadLocalMap数据结构
ThreadLocalMap数据结构
threadLocalHashCode
哈希函数和魔数。第一次看到这个会有点奇怪,实质上就是获取哈希散列表的下表的作用。
1//它在该ThreadLocal被构造的时候就会生成,相当于一个ThreadLocal的ID。这个是哈希散列表的下一个
2private final int threadLocalHashCode = nextHashCode();
3private static AtomicInteger nextHashCode =
4 new AtomicInteger();
5//ThreadLocal中定义了一个AtomicInteger,一个魔数0x61c88647,利用算法实现了元素的完美散列
6private static final int HASH_INCREMENT = 0x61c88647;
7//哈希函数
8private static int nextHashCode() {
9 return nextHashCode.getAndAdd(HASH_INCREMENT);
10}
其中这里设计散列算法,魔数 0x61c88647。
魔数的选取跟斐波那契散列有关。对应的十进制是1640531527。而按照斐波那契散列,魔数值应该为(根号5)/2*2^32=2654435769,这个值正好为unsigned int可以表示,int表示为-1640531527,恰好对应上述的十进制值。
1/** 2 * 3 * @ClassName:MagicHashCode 4 * @Description:ThreadLocalMap使用“开放寻址法”中最简单的“线性探测法”解决散列冲突问题 5 */ 6public class MagicHashCode { 7 //ThreadLocal中定义的hash魔数 8 private static final int HASH_INCREMENT = 0x61c88647; 9 10 public static void main(String[] args) { 11 hashCode(16);//初始化16 12 hashCode(32);//后续2倍扩容 13 hashCode(64); 14 } 15 16 /** 17 * 18 * @Description 寻找散列下标(对应数组小标) 19 * @param length table长度 20 * @author diandian.zhang 21 * @date 2017年12月6日上午10:36:53 22 * @since JDK1.8 23 */ 24 private static void hashCode(Integer length){ 25 int hashCode = 0; 26 for(int i=0;i<length;i++){ 27 hashCode = i*HASH_INCREMENT+HASH_INCREMENT;//每次递增HASH_INCREMENT 28 System.out.print(hashCode & (length-1));//求散列下标,算法公式 29 System.out.print(" "); 30 } 31 System.out.println(); 32 } 33}Entry数组为16,32,64对应的下标值,正好可以形成一个完美散列,其他非2的幂次不能形成完美散列,这解释上述table大小和容量必须是2的幂次,默认为16。
17 14 5 12 3 10 1 8 15 6 13 4 11 2 9 0 --》Entry[]初始化容量为16时,元素完美散列 27 14 21 28 3 10 17 24 31 6 13 20 27 2 9 16 23 30 5 12 19 26 1 8 15 22 29 4 11 18 25 0--》Entry[]容量扩容2倍=32时,元素完美散列 37 14 21 28 35 42 49 56 63 6 13 20 27 34 41 48 55 62 5 12 19 26 33 40 47 54 61 4 11 18 25 32 39 46 53 60 3 10 17 24 31 38 45 52 59 2 9 16 23 30 37 44 51 58 1 8 15 22 29 36 43 50 57 0 --》Entry[]容量扩容2倍=64时,元素完美散列以Entry大小16为例,计算如下:
因为int有符号的特性,32位int型最大2^31-1=2147483647,在大1就会变成最大负数,对unsigned型的2654435769转化为int并去除符号为1640531527。这个值和最大2147483648的差值为506952121。
1.第一个值就是魔数本身,看二进制最后四位,可以看出为7。

2.第二个值就是魔数的2倍,其实相当于会溢出一次,直接拿魔数减去差值为506952121,为1133579406。

3.第三个值是在2的基础上同样再减去506952121,为626627285

4.第四个值是在3的基础上同样减去506952121,为119675164。

接下来亦复如是,不操作下去了。
通俗的来讲用过散列算法,默认16个大小的数组,相当于从0-15共有16个数组下标。当某一个ThreadLocal初始化之后,就会通过哈希函数得到一个ThreadLocal的数值,我们这里称之为id。
1int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
上述结果i的值是Threadlocal的id和数组大小与的运算,其实跟求余运算相同,只是与运算更快,效率更高。最终i得到的是一个数组下标。举例说明,Entry数组大小16,ThreadLocal< Interger >的话值是固定的,这里暂定一个值,数组下标3。那么下次再有ThreadLocal< Interger >的值过来,还是会走到数组下标为3,这是固定的,除非Entry数组大小发生改变。
划分Entry的类型
了解到Entry数组和ThreadLocalMap的数据结构,那么这里首先将Entry数组分成三种类型,空类型(null Entry)、全类型(key存在,value可不存在)、部分回收类型(key被回收,value存在),如下图所示。
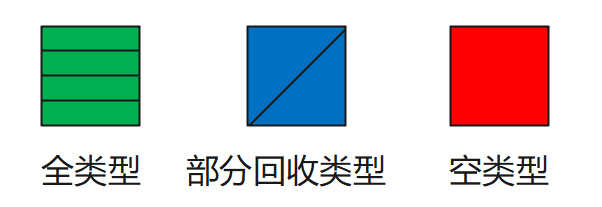 Entry类型
Entry类型
另外根据哈希散列算法,这边人为规定类型和散列顺序,即ThreadLocal<?>类型对应的firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1)的值。
表1 人为规定的散列表
| T\tab size | 16 | 32 | 64 |
|---|---|---|---|
| 尺子 | 7 | 7 | 7 |
| 白纸 | 14 | 14 | 14 |
| 钢笔 | 5 | 21 | 21 |
| 笔筒 | 12 | 28 | 28 |
| 铅笔 | 3 | 3 | 35 |
| 本子 | 10 | 10 | 42 |
| 袋子 | 1 | 17 | 49 |
| 夹子 | 8 | 24 | 56 |
| 墨水 | 15 | 31 | 63 |
| 梳子 | 6 | 6 | 6 |
| 镜子 | 13 | 13 | 13 |
| 电池 | 4 | 20 | 20 |
清理模式
在介绍set和get之前,先快速熟悉一下两种清理模式
1)expungeStaleEntry。探测式清理
2)cleanSomeSlots。启发式清理
1)expungeStaleEntry
1//传入的值对应table中的Entry为null或者k=null
2//返回的值对应table中Entry为null
3private int expungeStaleEntry(int staleSlot) {
4 Entry[] tab = table;
5 int len = tab.length;
6
7 // 清理过时的插槽,即把部分回收类型变成空类型
8 tab[staleSlot].value = null;
9 tab[staleSlot] = null;
10 size--;
11
12 //遇到null的时候会重新hash
13 Entry e;
14 int i;
15 for (i = nextIndex(staleSlot, len);
16 (e = tab[i]) != null;
17 i = nextIndex(i, len)) {
18 ThreadLocal<?> k = e.get();
19 //出现部分回收类型,置为空
20 if (k == null) {
21 e.value = null;
22 tab[i] = null;
23 size--;
24 } else {
25 //k不为null时候,重新hash函数
26 int h = k.threadLocalHashCode & (len - 1);
27 if (h != i) {
28 tab[i] = null;
29
30 //与Knuth 6.4算法R不同,我们必须扫描直到为空,因为多个条目可能已经过时
31 while (tab[h] != null)
32 h = nextIndex(h, len);
33 tab[h] = e;
34 }
35 }
36 }
37 //出现空类型,直接返回结果空类型的下标
38 return i;
39}
i)上述方法做了两件事,第一将传进来的值,变成null Entry(空类型)
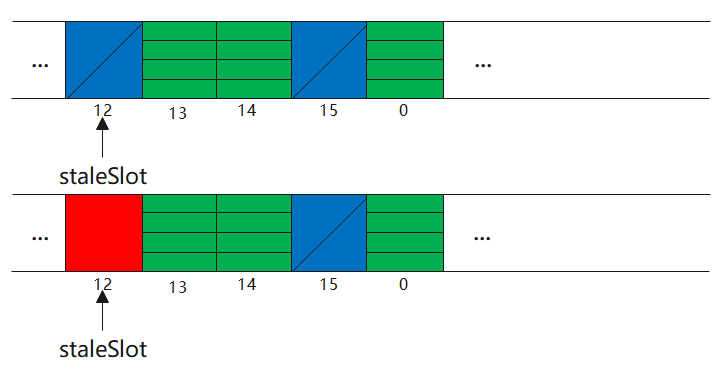
ii)分三种情况,遇到空类型,部分回收类型和全类型
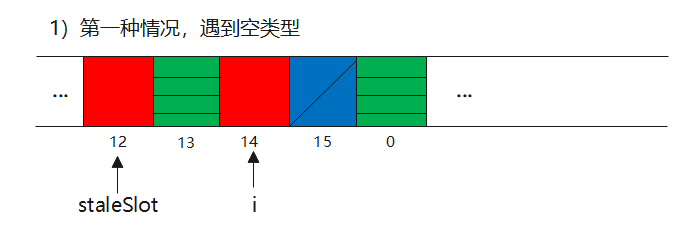
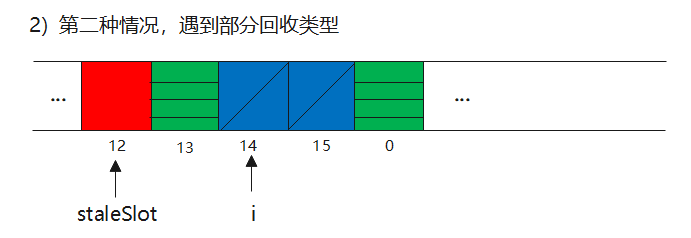
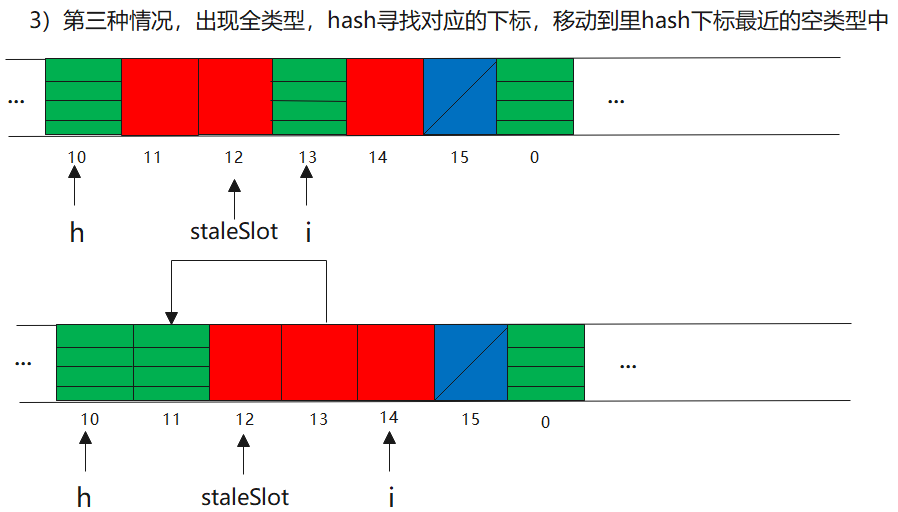
2)cleanSomeSlots
1//传入的值对应table中的Entry为null或者k!=null
2//如果在接下来的循环顺序5个Entry中没有找到k=null,则返回false
3//找到开始探测式清理,并重置循环5个Entry,最终返回true
4private boolean cleanSomeSlots(int i, int n) {
5 boolean removed = false;
6 Entry[] tab = table;
7 int len = tab.length;
8 do {
9 i = nextIndex(i, len);
10 Entry e = tab[i];
11 if (e != null && e.get() == null) {
12 n = len;
13 removed = true;
14 i = expungeStaleEntry(i);
15 }
16 } while ( (n >>>= 1) != 0);
17 return removed;
18}
这里面的n»>=1等于n=n»>1,意思是强制右移1位。
下列位需要循环顺序查找次数和对应的size表
表2 顺序查找次数
| 次数\size | 16 | 32 | 64 |
|---|---|---|---|
| 1 | 8 | 16 | 32 |
| 2 | 4 | 8 | 16 |
| 3 | 2 | 4 | 8 |
| 4 | 1 | 2 | 4 |
| 5 | 0 | 1 | 2 |
| 6 | / | 0 | 1 |
| 7 | / | / | 0 |
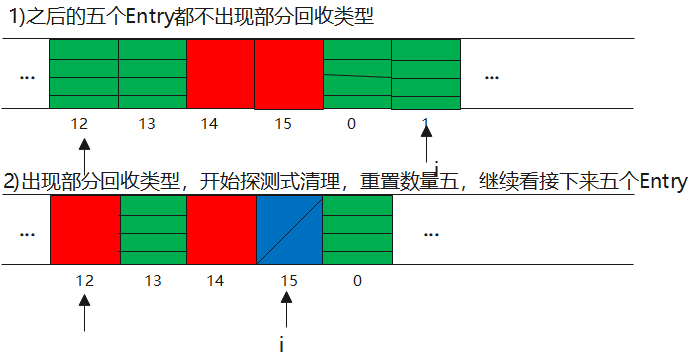
最终在重置后的五个Entry类型中为出现部分回收类型则结束清理。
set
这个方法应该是本文最复杂最难理解的一个方法,这里会将其拆解开来,分成set的三种情况。
1private void set(ThreadLocal<?> key, Object value) {
2 //set的流程相对来说会比较复杂,往往通过hash下标对应不上
3 Entry[] tab = table;
4 int len = tab.length;
5 int i = key.threadLocalHashCode & (len-1);
6
7 for (Entry e = tab[i];
8 e != null;
9 e = tab[i = nextIndex(i, len)]) {
10 ThreadLocal<?> k = e.get();
11 //情况2:找不到对应的k,循环下一个查找,直到找到当前的k为key,那么替换value值
12 if (k == key) {
13 e.value = value;
14 return;
15 }
16 //情况4:找不到对应的k,循环下一个查找,直到找到一个部分回收类型
17 if (k == null) {
18 replaceStaleEntry(key, value, i);
19 return;
20 }
21 }
22
23 //情况1:下一个Entry为空类型,构造一个Entry放入,并作启发式清理
24 //情况3:Entry类型一直为全类型,但是k != key,直到遇到空类型,并做启发式清理
25 tab[i] = new Entry(key, value);
26 int sz = ++size;
27 if (!cleanSomeSlots(i, sz) && sz >= threshold)
28 rehash();
29}
上述主要描述四种情况,实际上情况1和情况3是可以重合的,所以其实只存在三种情况
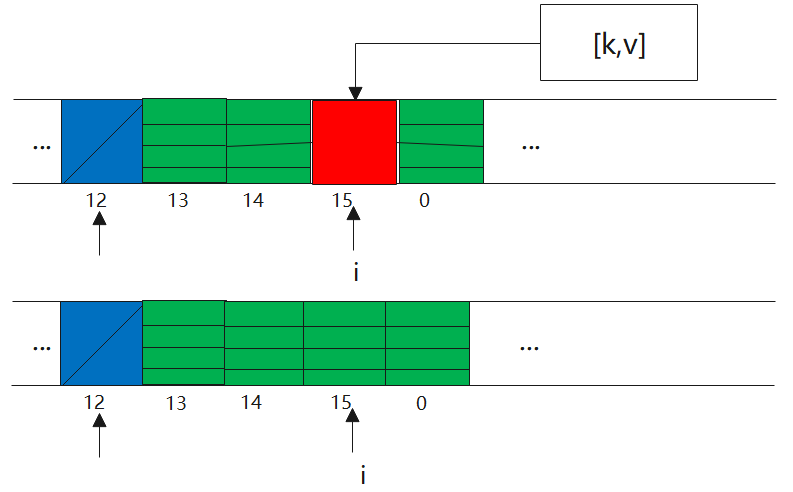
1)遇到Entry空类型,构造一个k-v的Entry,然后启发式清理
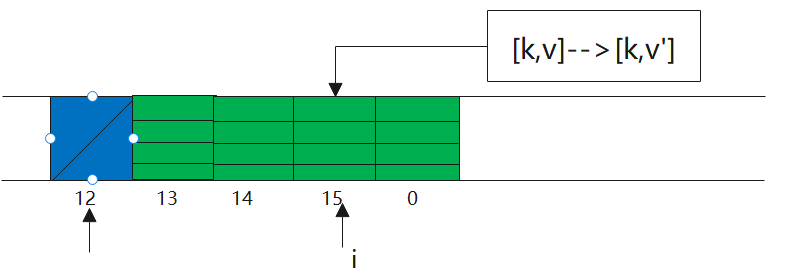
2)找不到对应的k,循环下一个查找,直到找到当前的k为key,那么替换value值
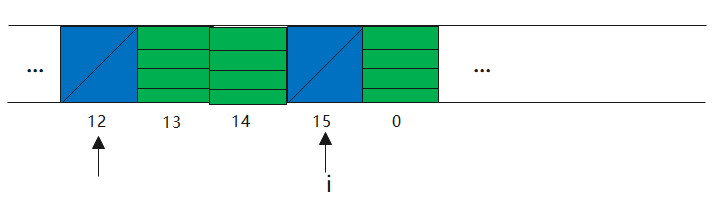
3)找不到对应的k,循环下一个查找,直到找到一个部分回收类型,这种类型会在replaceStaleEntry方法中详解。
replaceStaleEntry
第三种情况的方法,按逻辑来又分为向前找null Entry、向后替换、清理部分回收类型,其中向后替换又存在两种情况。
1//set过程中遇到部分回收类型
2private void replaceStaleEntry(ThreadLocal<?> key, Object value,
3 int staleSlot) {
4 Entry[] tab = table;
5 int len = tab.length;
6 Entry e;
7
8 //检查是否勋在部分回收类型,避免由于垃圾回收造成这种类型在散列表中持续增加
9 int slotToExpunge = staleSlot;
10 for (int i = prevIndex(staleSlot, len);
11 (e = tab[i]) != null;
12 i = prevIndex(i, len))
13 if (e.get() == null)
14 slotToExpunge = i;
15
16 //找到全类型和空类型
17 for (int i = nextIndex(staleSlot, len);
18 (e = tab[i]) != null;
19 i = nextIndex(i, len)) {
20 ThreadLocal<?> k = e.get();
21
22 //找到key就交换,使用hash下标来维护哈希表的顺序
23 if (k == key) {
24 e.value = value;
25
26 tab[i] = tab[staleSlot];
27 tab[staleSlot] = e;
28
29 // 开始清理
30 if (slotToExpunge == staleSlot)
31 slotToExpunge = i;
32 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
33 return;
34 }
35 //向后没有找到部分回收类型,那么开始扫描仍是第一个条目
36 if (k == null && slotToExpunge == staleSlot)
37 slotToExpunge = i;
38 }
39
40 // 如果没有找到key,那么新建一个Entry,value为null
41 tab[staleSlot].value = null;
42 tab[staleSlot] = new Entry(key, value);
43
44 if (slotToExpunge != staleSlot)
45 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
46}
这个方法看起来很多,实际上完成了三件事。
1)向前找null Entry,即空类型

2)向后替换
这里面又分为两种情况
第一种情况:k == key直接命中,然后替换
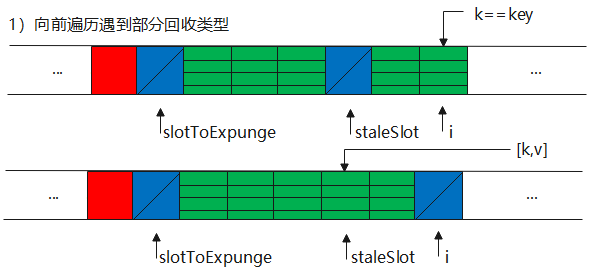
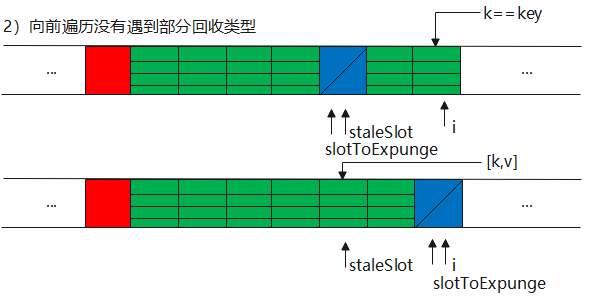
第二种情况:非命中,则包括空类型,部分回收类型,slotExpunge会记录这种类型的下标
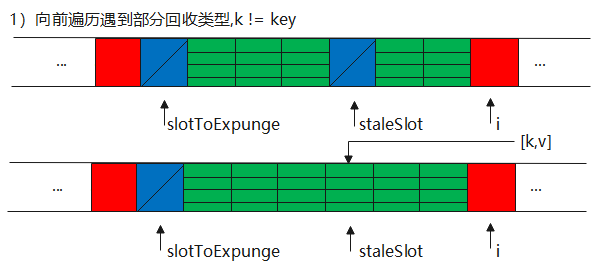
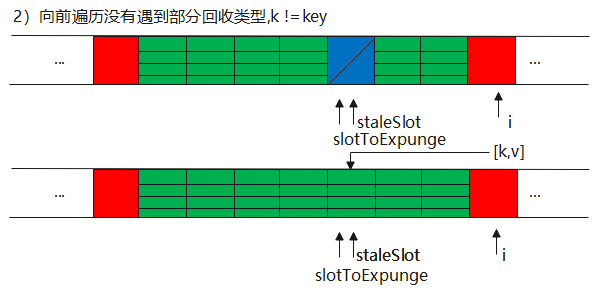
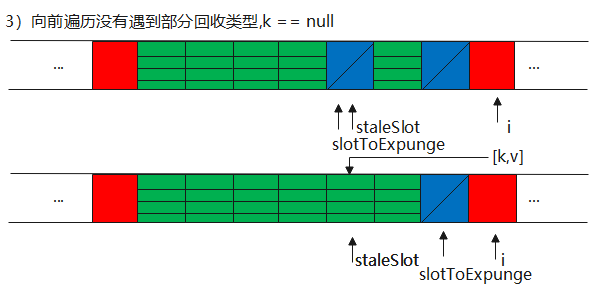
其实说白了也就是两种情况,唯一的区别就是slotExpunge下标不一样,会影响后续的清理,在第二部这个逻辑上无差别。
3)探索式清理和启发式清理
这里详细看上面两种清理的解释
扩容机制
这里涉及到了扩容机制
1//当大小大于等于扩容阈值,才有机会扩容
2threshold = len * 2 / 3;
3sz >= threshold
4//探测式清理完成之后,再次比较大小,一半的len
5size >= threshold - threshold / 4
表3 不同size的扩容机制
| 方法\size | 16 | 32 | 64 |
|---|---|---|---|
| rehash | 10 | 21 | 42 |
| resize | 8 | 16 | 32 |
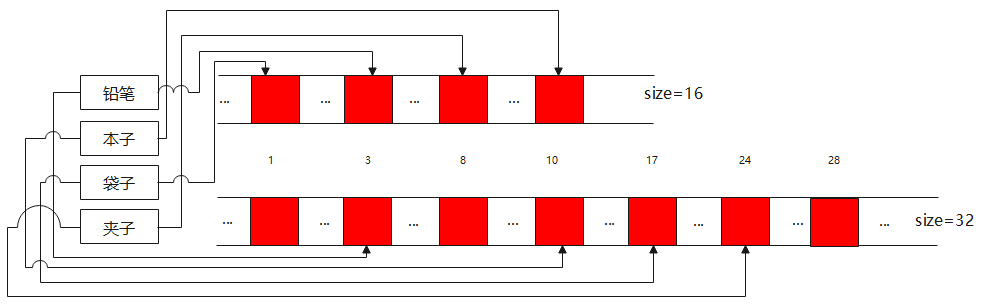
以铅笔,本子,袋子,夹子为例,在size16的时候,分别为哈希散列下标为3,10,1,8;size为32的时候,分别哈希散列下标为3,10,17,24。
get
相对于set来说,getMap的方法,更加容易理解。
1private Entry getEntry(ThreadLocal<?> key) {
2 int i = key.threadLocalHashCode & (table.length - 1);
3 Entry e = table[i];
4 //直接命中
5 if (e != null && e.get() == key)
6 return e;
7 else
8 //非直接命中
9 return getEntryAfterMiss(key, i, e);
10}
这里面的方法,主要是两种情况
1)直接命中
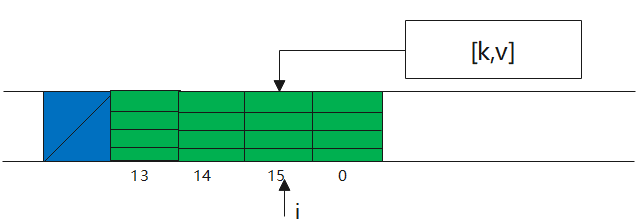
2)不直接命中
这个会调用到getEntryAfterMiss方法去。
getEntryAfterMiss
1//非直接命中,通过循环依次遍历,看能否找到
2private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
3 Entry[] tab = table;
4 int len = tab.length;
5
6 while (e != null) {
7 ThreadLocal<?> k = e.get();
8 if (k == key)
9 return e;
10 if (k == null)
11 expungeStaleEntry(i);
12 else
13 i = nextIndex(i, len);
14 e = tab[i];
15 }
16 return null;
17}
当非直接命中的时候,这个时候有分成三种情况。
1)k != key(全类型),return e
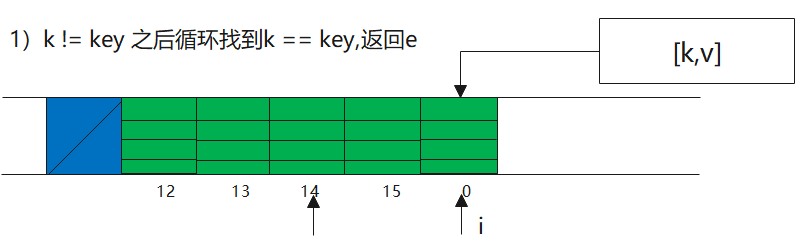
2)null Entry(空类型),return null Entry
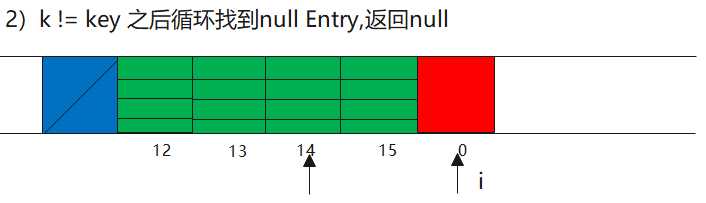
3)k == null(部分回收类型),清理完之后继续循环
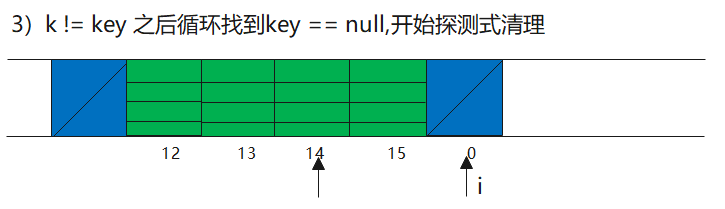
可以说逻辑还是非常清晰的,返回值只能是命中的值或者是null。
remove
1private void remove(ThreadLocal<?> key) {
2 Entry[] tab = table;
3 int len = tab.length;
4 int i = key.threadLocalHashCode & (len-1);
5 for (Entry e = tab[i];
6 e != null;
7 e = tab[i = nextIndex(i, len)]) {
8 if (e.get() == key) {
9 e.clear();
10 expungeStaleEntry(i);
11 return;
12 }
13 }
14}
remove方法相对于getEntry和set方法比较简单,直接在table中找key,如果找到了,把弱引用断了做一次段清理。
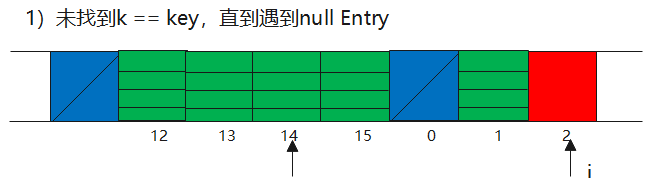
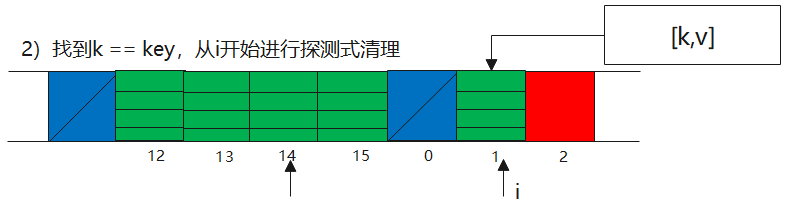
这边的逻辑其实只有在k == key的时候才做清理,其他k != key,k == null的时候继续下移一个,直到遇到null Entry退出。
补充
关于ThreadLocal匿名方式获取value
通常来说,如果没有初始化一个ThreadLocal的时候没有set过类型,直接获取,返回的是一个空的value,如下图所示。
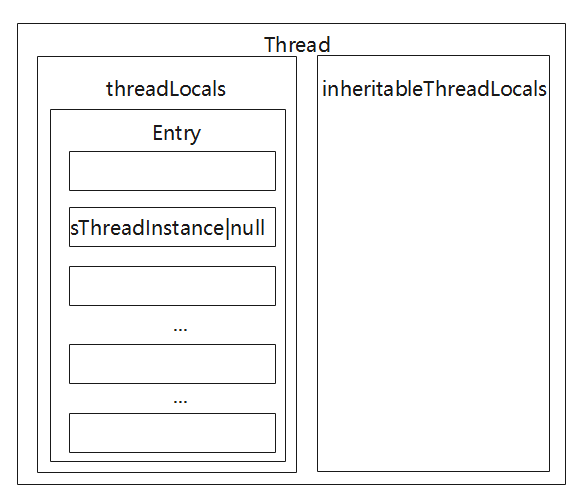
但是通过匿名函数的写法,复写initialValue方法,可以使得value不为null。
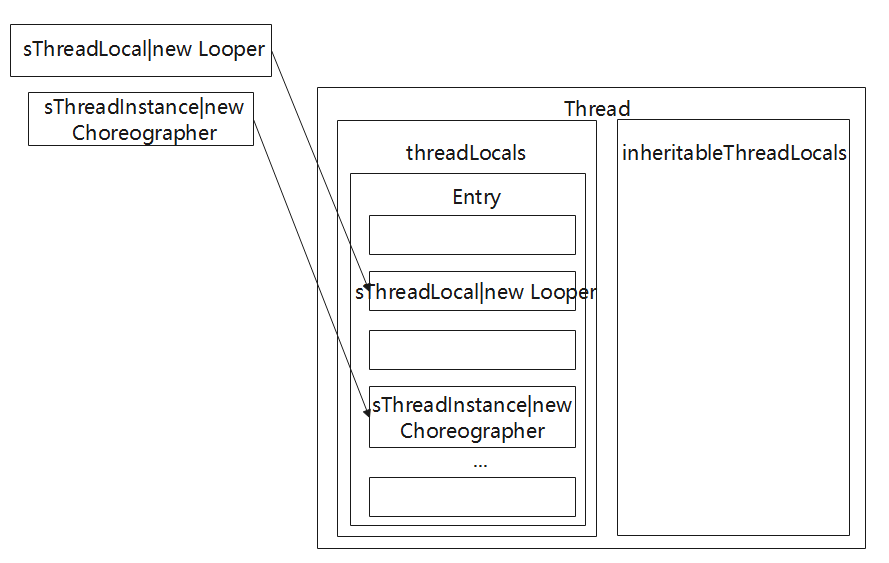
以Choreographer.java源码中的实例说明
1//frameworks/base/core/java/android/view/Choreographer.java#getInstance
2public static Choreographer getInstance() {
3 return sThreadInstance.get();
4}
5
6// Thread local storage for the choreographer.
7private static final ThreadLocal<Choreographer> sThreadInstance =
8 new ThreadLocal<Choreographer>() {
9 @Override
10 protected Choreographer initialValue() {
11 Looper looper = Looper.myLooper();
12 if (looper == null) {
13 throw new IllegalStateException("The current thread must have a looper!");
14 }
15 Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
16 if (looper == Looper.getMainLooper()) {
17 mMainInstance = choreographer;
18 }
19 return choreographer;
20 }
21};
其中在get过程中,通过上文的分析可知,匿名内部类复写setInitialValue。在匿名内部类中定义一个value,那么实际的value就不为null,如下图所示。
1//返回当前线程的 this 局部变量map保存的线程副本值
2//如果没有找到该线程副本,返回线程本地的当前线程值
3public T get() {
4 Thread t = Thread.currentThread();
5 ThreadLocalMap map = getMap(t);
6 if (map != null) {
7 ThreadLocalMap.Entry e = map.getEntry(this);
8 if (e != null) {
9 @SuppressWarnings("unchecked")
10 T result = (T)e.value;
11 return result;
12 }
13 }
14 return setInitialValue();
15}
16
17//初始化,这个方法会覆写原来的set
18private T setInitialValue() {
19 T value = initialValue();
20 Thread t = Thread.currentThread();
21 ThreadLocalMap map = getMap(t);
22 if (map != null)
23 map.set(this, value);
24 else
25 createMap(t, value);
26 return value;
27}
28
29//每个线程只有一次,跟remove配套使用,可供子类覆写,这里的匿名内部类复写了
30protected T initialValue() {
31 return null;
32}
总结
整体的Threadlocal源码解析分析完了,主要是更加直观清晰的了解到ThreadLocal的组成部分和数据结构。接下来,会有Threadlocal的具体用途,尽请期待。
猜你喜欢
参考
[1] 并发编程艺术, ThreadLocal源码阅读一:散列算法,魔数 0x61c88647 学习, 2020.
[2] 活在夢裡, ThreadLocal源码解读, 2017.
[3] 只会一点java, ThreadLocal终极源码剖析-一篇足矣!, 2017.